Linux Command Line and Shell Scripting Bible Notes
第六章 使用 Linux 环境变量
6.7 数组变量
环境变量有一个很酷的特性就是, 它们可作为数组使用.
要给某个环境变量设置多个值, 可以把值放在括号里, 值与值之间用空格分隔:
1 | |
使用索引值引用:
1 | |
从 0 开始.
要显示整个数组变量, 可用星号作为通配符放在索引值的位置:
1 | |
可以使用 unset 来删除数组中的某个值, 但其他元素的位置不变, 只是被删除的这个值的位置此时的值为空:
1 | |
可以删掉整个数组:
1 | |
第十一章 构建基本脚本
11.4 使用变量
多个命令在同一行执行,使用分号隔开:
1 | |
如果文本文件开头的最前面两个字符是#!,那么后面跟着的就是用来执行这个文件的程序路径.
shell 通过PATH环境变量来查找命令.
引用当前目录下的文件,可以使用shell中使用单点操作符:
1 | |
对于文件而言,全权限值为666, 对于目录而言,全权限值为777.
默认权限值为全权限值减去umask变量的值.
11.4.2 用户变量
在变量、等号和值之间不能出现空格.
shell 脚本会自动决定变量值的数据类型.
引用一个变量值时需要使用美元符,而引用变量来对其进行赋值时不要使用美元符:
1 | |
没有美元符,shell会将变量名解释成普通的文本字符串.
11.4.3 命令替换
命令替换允许你将shell命令的输出赋给变量, 有两个格式:
1 | |
如:
1 | |
命令替换会创建一个子shell来运行对应的命令.
11.5 重定向输入和输出
11.7 执行数学运算
11.7.1 expr命令
expr命令允许在命令行上处理数学表达式:
1 | |
对于那些容易被shell错误解释的字符,在它们传入expr命令之前,需要使用shell的转义字符将其标出来:
1 | |
11.7.2 使用方括号
在bash中,在将一个数学运算结果赋给某个变量时,可以使用美元符和方括号($[ operation ])将数学表达式围起来:
1 | |
不用担心shell会误解.
bash shell 数学运算符只支持整数运算.
z shell 提供了完整的浮点运算。
11.7.3 浮点解决方案
使用bash内建的计算器bc.
可以在shell提示符下通过bc命令访问bash计算器.
浮点运算是由内建变量scale控制,用于设置你希望在计算结果中保留的小数位数.
使用-q命令行选项可以不显示bash计算器的欢迎信息.
在脚本中使用bc
变量名似乎不能是大写字母.
利用命令替换, 基本格式如下:
1 | |
使用那联输入重定向(inline input redirection), 需指定一个文本标记来划分输入数据的开始和结尾,文本标记可以为任意字符串:
1 | |
如:
1 | |
在bash计算器中创建的变量只在bash计算其中有效,不能在shell脚本中使用.
计算幂函数:
1 | |
开根号:
1 | |
11.8 退出脚本
退出状态码(exit status),一个0~255的整数值.
11.8.1 查看退出状态码
变量$?来保存上个已执行命令的退出状态码.
成功结束的命令的退出状态码是0.
无效命令会返回一个exit status为127.
exit status为126表示用户没有执行命令的正确权限。
11.8.2 exit命令
指定exit status退出.
第12章 使用结构化命令
12.1 使用if-then语句
格式:
1 | |
查看if后面command的exit status, 是0, 则执行.
then部分可以有多条命令.
12.2 if-then-else语句
格式:
1 | |
else部分也可以包含多条命令.
12.3 嵌套if
使用嵌套的if-then语句.
使用elif语句:
1 | |
12.4 test 命令
运用test命令通过if-then语句测试其他条件.
如果test命令中列出的条件成立,test命令就会退出并返回exit status 0.
格式:
1 | |
如:
1 | |
如果不写test命令的condition部分,它会以非零的退出状态码退出,并执行else语句快.
可以用test命令确定变量中是否有内容.
另一种测试方法,不需用test命令:
1 | |
注意第一个方括号之后和第二个方括号之前必须加上一个空格.
test命令可以判断三类条件:
1. 数值比较
2. 字符串比较
3. 文件比较
12.4.1 数值比较
不能在test命令中使用浮点值。
12.4.2 字符串比较
1. 比较时大于号和小于号必须转义。
2. 大于和小于顺序和sort命令采取的不同。比较使用的是ASCII顺序, 小写大于大写。sort命令使用的是本地英语,小写字母出现在大写字母之前.
使用-n和-z参数检查一个变量是否含有数据:
1 | |
空的和未初始化的变量会对shell脚本测试造成灾难性的影响.
12.4.3 文件比较
测试Linux文件系统上文件和目录的状态.
还是使用参数比较.
12.5 复合条件测试
有两种布尔运算符可用:
1 | |
12.6 if-then 的高级特性
bash shell 提供了两项可在 if-then 语句中使用的高级特性:
1 | |
12.6.1 使用双括号
格式:
1 | |
不需要将双括号中表达式里的大于号转义。
12.6.2 使用双方括号
格式:
1 | |
这里的expression使用了test命令中的标准字符串比较,但它提供了模式匹配 pattern matching.
这里用双等号==其右侧为一个正则表达式.
12.7 case 命令
case 命令采用列表格式来检查单个变量的多个值。
格式:
1 | |
case 命令会将指定的变量与不同模式进行比较,如果变量和模式是匹配的,那么shell会执行该模式指定的命令.
13 更多的结构化命令
13.1 for 命令
格式:
1 | |
13.1.2 读取列表中的复杂值
1 | |
如:
1 | |
在某个值的两边使用双引号时,shell并不会将双引号当成值的一部分.
13.1.3 从变量读取列表
13.1.4 从命令读取值
13.1.5 更改字段分隔符
环境变量IFS, Internal Field Separator. 定义了bash shell 用作字段分隔符的一系列字符.
默认为:
1 | |
更改为只识别换行符:
1 | |
在改变IFS之前保存原来的IFS值:
1 | |
指定多个字符:
1 | |
直接串起来.
13.2 C语言风格的for命令
和C语言风格的类似,但有一些细微的不同, 基本格式:
1 | |
没有遵循bash shell标准的for命令:
1 | |
13.3 while 命令
格式:
1 | |
13.3.2 定义多个测试命令
1 | |
只有最后一个测试命令的exit status用来决定退出.
每个测试命令都出现在单独的一行。
在每次迭代中所有的测试命令都会被执行, 包括测试命令失败的那一次迭代,其测试条件依然会全部执行.
13.4 until 命令
只有测试命令的exit status不为0, bash shell才会执行循环内的命令,其工作模式和while相反, 即测试条件成功时退出.
格式:
1 | |
13.7 控制循环
1 | |
特殊用法:
1 | |
n指定了要跳出的循环层级, 默认情况下n为1.
1 | |
13.8 处理循环的输出
通过在done命令之后添加一个处理命令实现:
1 | |
13.9 实例
13.9.1 查找可执行文件
1 | |
13.9.2 创建多个用户账户
把数据从文件中送入while命令, 在while命令尾部使用一个重定向符就可以了:
1 | |
第十四章 处理用户输入
14.1 命令行参数
14.1.1 读取参数
positional parameter, 位置参数,一个特殊变量,由bash shell分配给输入到命令行的所有参数. 也就是 $0, $1 这些.
$0是程序名,$1是第一个参数,直到$9.
将文本字符串作为参数传递时,引号并非数据得一部分, 它们只是表明数据的起始位置.
在第九个变量之后,必须在变量数字周围加上花括号, 如${10}.
14.1.2 读取脚本名
当传给$0变量的实际字符串不仅仅是脚本名,而是完整的脚本路径时,变量$0就会使用整个路径.
basename命令会返回不包含路径的脚本名.
1 | |
14.1.3 测试参数
在使用参数前一定要检查其中是否存在数据。
14.2 特殊参数变量
14.2.1 参数统计
特殊变量$#记录命令行参数的个数.
通过使用前测试参数的总数:
1 | |
同时,${!#}表示最后一个命令行参数. 在花括号内不能使用美元符号,需将其替换为!.
14.2.2 抓取所有的数据
$*变量会将命令行上提供的所有参数当作一个单词保存.
$@变量会将命令行上提供的所有参数当作统一字符串中的多个独立的单词.
注意使用时添加双引号.
14.3 移动变量
shift命令,将每个参数变量向左移动一个位置,$0不会改变.
给shift命令提供参数,可以一次移动多个位置.
14.4 处理选项
选项是跟在单破折号后面的单个字母,他能改变命令的行为。
14.4.1 查找选项
用case语句来判断某个参数是否为选项.
分离选项和参数
shell会用双破折号(–)来表明选项列表结束,其后的参数会被当作参数处理而不是选项。
1 | |
利用shift每调用一个选项就移除一个。
在Linux中,合并选项是一个很常见的做法。
14.4.2 使用getopt命令
这个命令的作用在于 格式化命令行参数.
getopt命令可以识别命令行参数.
getopt命令可以接受一系列任意形式的命令行选项和参数,并自动将它们转换成适当的格式:
1 | |
在每个需要参数值的选项字母后面加一个冒号:
1 | |
这时, 命令行参数就被格式化为:
1 | |
c 和 d 是两个命令行选项, 所以把 -cd 变成了 -c -d.
因为 -d 没有参数, 所以后面会有 -- 来分隔.
在这里的意思就是, b 这个选项需要参数.
2. 在脚本中使用 getopt
set 命令能够处理 shell 中的各种变量
14.4.3 使用更高级的 getopts
getopts 内建于 bash shell, 比 getopt 多了一些扩展功能.
每次调用 getopts, 它一次只处理命令行上检测到的一个参数. 处理完所有参数后, 它会退出并返回一个大于 0 的推出状态码.
格式:
1 | |
要去掉错误信息的话, 可以在 optstring 之前加一个冒号.
getopts 命令会将当前参数保存在命令行中定义的 variable 中.
getopts 命令会用到两个环境变量:
- OPTARG : 会保存选项后跟的参数值
- OPTIND : 保存参数列表中 getopts 正在处理的参数的位置, 毕竟这个函数一次只处理一个选项. 第一个选项的位置为 1
getopts 命令解析命令行选项时会移除开头的单破折号, 因此在 case 中定义时不用单破折号.
getopts 命令可以在参数值之间加空格, 如 "test1 test2", 也可以把选项字母和参数值放在一起使用, 而不加空格 ./test.sh -abtest1.
getopts 还能将命令行上找到的所有未定义的选项统一输出成问号.
在 getopts 每处理一个选项, 其会把 OPTIND 环境变量值加一.
14.5 将选项标准化
Linux 命令行中的选项好多已经有了不成文的含义.
14.6 获取用户输入
14.6.1 基本的读取
read 命令从标准输入或另一个文件描述符号中接受输入, 在收到输入后, read 命令会将数据放进一个变量.
例子:
1 | |
这里 echo 的 -n 选项表示不会在字符串末尾输出换行符.
这里, read 把读取的值存入 name 这个变量.
read 的 -p 选项, 允许在命令行直接指定提示符:
1 | |
这里 Please enter your age: 就和之前使用 echo 是一样的.
可以指定多个变量.
如果不指定变量, 值会被存在 REPLY 这个环境变量中.
14.6.2 超时
使用 -t 选项, 指定 read 命令等待输入的秒数, 当计时器过期后, read 命令会返回一个非零退出状态码.
使用 -n 选项, 可以让 read 命令在读取指定字符数后退出. 如 read -n1 表示接受单个字符
14.6.3 隐藏方式读取
-s 选项, 避免在 read 命令中输入的数据出现在显示器上, 实际上, 数据会被显示, 只是 read 命令会将文本颜色设成跟背景色一样.
14.6.4 从文件中读取
每次调用 read 命令, 他都会从文件中读取一行文本, 当文件中再没有内容时, read 命令退出并返回非零状态码.
最常见的方法是对文件使用 cat 命令, 将结果通过管道直接传给含有 read 命令的 while 命令.
1 | |
第15章 呈现数据
15.1 理解输入和输出
15.1.1 标准文件描述符
Linux 系统将每个对象当作文件处理.
Linux 用文件描述符 (file descriptor) 来标识每个文件对象.
每个进程一次最多可以有九个文件描述符, bash shell 保留了前三个文件描述符.
- 0 SIDIN 标准输入
- 1 STDOUT 标准输出
- 2 STDERR 标准错误
当命令生成错误消息时, shell 并未将错误消息重定向到输出重定向文件.
默认情况下, STDERR 文件描述符和 STDOUT 文件描述符指向同样的地方.
15.1.2 重定向错误
1. 只重定向错误
可以选择只重定向错误消息, 将该文件描述符放在重定向符号前, 该值必须紧紧地放在重定向符号前.
1 | |
2. 重定向错误和数据
需要用两个重定向符号, 且在符号前面放上待重定向数据对应的文件描述符:
1 | |
可以利用 &> 这个特殊的重定向符号, 把 STDOUT 和 STDERR 重定向到同一个文件.
为了避免错误信息散落在输出文件中, 相较于标准输出, bash shell 自动赋予了错误消息更高的优先级.
15.2 在脚本中重定向输出
有两种方法在脚本中重定向输出:
- 临时重定向行输出
- 永久重定向脚本中的所有输出
15.2.1 临时重定向
在重定向到文件描述符时, 必须在文件描述符数字之前加一个 &:
1 | |
默认情况下, Linxu 会将 STDERR 导向 STDOUT, 如果在运行脚本时重定向了 STDERR, 脚本中所有导向 STDERR 的文本都会被重定向.
15.2.2 永久重定向
可以用 exec 命令告诉 shell 在执行脚本期间重定向某个特定的文件描述符:
1 | |
exec 命令会启动一个新 shell 并将 STDOUT 文件描述符重定向到文件. 这里实际上把 1 这个文件描述重新分配给了 testout 这个文件.
exec 在 man page 中的描述为: execute commands and open, close, or copy file descriptors.
15.3 在脚本中重定向输入
exec 命令允许你将 STDIN 重定向到 Linux 系统上的文件中:
1 | |
如 :
1 | |
15.4 创建自己的重定向
15.4.1 创建输出文件描述符
可以用 exec 命令来给输出分配文件描述符.
一旦将另一个文件描述符分配给一个文件, 这个重定向就会一直有效, 直到你重新分配.
1 | |
15.4.2 重定向文件描述符
1 | |
把文件描述符 3 指向文件描述符 1.
1 | |
恢复.
15.4.3 创建输入文件描述符
在重定向到文件之前, 先将 STDIN 文件描述符保存到另外一个文件描述符, 然后在读取完文件之后再将 STDIN 恢复到它原来的位置:
1 | |
15.4.4 创建读写文件描述符
可以打开单个文件描述符来作为输入和输出.
任何读或写都会从文件指针上次的位置开始, 比如你先用这个文件描述符输出了一行, 这时这个指针就指向这一行的末尾了, 如果你这个时候输入一段文本, 这个文本就会插入到这个指针所指的位置, 而不是文件的末尾.
15.4.5 关闭文件描述符
如果你创建了新的输入或输出文件描述符, shell 会在脚本退出时自动关闭它们.
在脚本结束前手动关闭文件描述符, 需要将它重定向到特殊符号 &-:
1 | |
在关闭文件描述符后, 如果你随后在脚本中打开了同一个文件, shell 会用一个新文件来替换已有的文件, 意思就是其内容会被覆盖.
15.5 列出打开的文件描述符
使用 isof 命令列出 Linux 系统打开的所有文件描述符.
15.6 阻止命令输出
可以将 STDERR 的输出从定向到叫 null 文件的特殊文件.
shell 输出到 null 文件的任何数据都不会保存, 全部都会被丢弃.
在 Linux 系统上 null 文件的标准位置是 /dev/null.
也可以用 /dev/null 作为输入文件, 其能够快速清除现有文件中的数据.
1 | |
15.7 创建临时文件
Linux 使用 /tmp 目录来存放不需要用就保存的文件, 大多数 Linux 发行版配置了系统在启动时自动删除 /tmp 目录的所有文件.
mktemp 命令可以在 /tmp 目录中创建一个唯一的临时文件, shell 会创建这个文件, 但不用默认的 umask 值. 它会将文件的读和写权限分配给文件的属主, 并将你设成文件的属主.
15.7.1 创建本地临时文件
要用 mktemp 命令在本地目录中创建一个唯一文件, 需要指定一个文件名模板, 模板可以包含任意文本文件名, 在文件名末尾加上 6 个 X 就行了, mktemp 命令会用 6 个字符码替换这 6 个 X, 从而保证文件名在目录中唯一.
将文件名保存在变量中:
1 | |
15.7.2 在 /tmp 目录创建临时文件
使用 -t 选项, 其会强制 mktemp 命令来到系统的临时目录来创建该文件, 在使用这个特性时, mktemp 命令会返回用来创建临时文件时的全路径.
15.7.3 创建临时目录
-d 选项告诉 mktemp 创建一个临时目录.
15.8 记录消息
使用特殊的 tee 命令, 可以将输出同时发送到显示器和日志文件.
它会将从 STDIN 过来的数据同时发送到两处, 一处是 STDOUT, 一处是 tee 命令行所指定的文件:
1 | |
可以配合管道符 |.
如果想将数据追加到文件, 必须使用 -a 选项.
第16章 控制脚本
16.1 处理信号
16.1.1 重温 Linux 信号
默认情况下, bash shell 会忽略收到的任何 SIGQUIT (3) 和 SIGTERM (15) 信号.
16.1.2 生成信号
16.1.3 捕获信号
trap 命令允许你来指定 shell 及脚本要监看并从 shell 中拦截的 Linux 信号.
格式:
1 | |
使用 trap 命令来忽略信号如:
1 | |
trap 命令会在每次检测到 SIGINIT 信号时显示一行文本, 并捕获这个信号, 其会阻止用户用 bash shell 的组合键 Ctrl+C 来停止程序.
16.1.4 捕获脚本退出
要捕获脚本的退出 (也就是脚本退出这个行为), 在 trap 命令后加上 EXIT 信号:
1 | |
在脚本退出时, 会打印 Goodbye...
16.1.5 修改或移除捕获
在脚本的不同地方进行捕获, 就还是用 trap 命令, 只是后面的选项是新的, 这时脚本要捕获的信号就被修改了.
可以删除已设置好的捕获, 在 trap 命令与希望恢复默认行为的信号列表之间加上两个破折号 (单个也行).
如要恢复, 即不再对 SIGINT 进行捕获:
1 | |
16.2 以后台模式运行脚本
16.2.1 后台运行脚本
在命令之后加上 & 符号.
当后台进程运行时, 它仍然会使用终端显示器来显示 STDOUT 和 STDERR 消息.
最好是将后台运行的脚本的 STDOUT 和 STDERR 重定向.
16.3 在非控制台下运行脚本
nohup 命令运行了另外一个命令来阻断所有发送给该进程的 SIGHUP 信号, 这会在退出终端会话时阻止进程退出.
1 | |
由于 nohup 命令会解除终端与进程的关联, 进程也就不再同 STDOUT 和 STDERR 联系在一起, 为了保存该命令产生的输出, nohup 命令会自动将 STDOUT 和 STDERR 的消息重定向到一个名为 nohuo.out 文件中.
16.4 作业控制
脚本用 $$ 变量来显示 Linux 系统分配给该脚本的 PID.
16.6 定时控制脚本
在登录时运行的脚本应该放入 $HOME/.bash_profile.
每次启动一个新的 shell, bash shell 都会运行 .bashrc 文件.
.bashrc 文件通常要执行两次, 一次是当你登入 bash shell, 另一次是当你启动一个 bash shell.
第17章 创建函数
17.1 基本的脚本函数
函数是一个脚本代码块, 你可以为其命名并在代码中任何位置重用.
17.1.1 创建函数
有两种格式可以在 bash shell 脚本中创建函数:
第一种格式采用关键字 function:
1 | |
第二种格式:
1 | |
函数名后的空括号表明正在定义一个函数.
17.1.2 使用函数
指定函数名.
如果在函数被定以前使用函数, 会收到一条错误信息.
如果重定义了函数, 新定义会覆盖原来函数的定义, 且不会产生任何错误信息.
17.2 返回值
bash shell 会把函数当作一个小型脚本, 运行结束时会返回一个退出状态码.
17.2.1 默认退出状态码
默认情况下, 函数的退出状态码是函数中最后一条命令返回的推出状态码.
使用函数的默认退出状态码是很危险的.
17.2.2 使用 return 命令
bash shell 用 return 命令来退出函数并返回特定的退出状态码.
两个注意事项:
- 函数一结束就取返回值
- 退出状态码必须是 0 ~ 255
如果在使用 $? 变量提取函数返回值之前执行了其他命令, 函数的返回值就会丢失.
如:
1 | |
17.2.3 使用函数输出
获得函数的输出, 并保存在变量中:
1 | |
或:
1 | |
获取输出, 和返回值不同.
17.3 在函数中使用变量
17.3.1 向函数传递参数
同样还是用 $#, $1 这些特殊变量.
在脚本中指定函数时, 必须将参数和函数放在同一行:
1 | |
由于函数使用特殊参数环境变量作为自己的参数值, 因此它无法直接获取脚本在命令行中的参数值.
17.3.2 在函数中处理变量
函数中定义的变量与普通变量的作用域不同.
函数使用两种类型的变量:
- 全局变量
- 局部变量
1. 全局变量
全局变量是在 shell 脚本中任何地方都有效的变量.
默认情况下, 在脚本中定义的任何变量都是全局变量, 在函数外定义的变量可在函数内正常访问.
2. 局部变量
无需在函数中使用全局变量, 函数内部使用的任何变量都可以被声明成局部变量, 使用 local 关键词:
1 | |
也可在变量赋值语句中使用 local 关键字:
1 | |
local 关键词保证了变量只局限在该函数中.
17.4 数组变量和函数
17.4.1 向函数传递数组参数
17.4.2 从函数返回数组
17.5 函数递归
函数可以调用自己来得到结果.
17.6 创建库
bash shell 允许创建函数库文件, 然后在多个脚本中引用该库文件.
第一步是创建一个包含脚本中所需函数的共用库文件.
如:
1 | |
第二步是在用这个函数的脚本中包含该库文件.
使用 source 命令, source 命令有个快捷的别名, 称做点操作符 (dot operator):
1 | |
等价于:
1 | |
17.7 在命令行上使用函数
一旦在 shell 中定义了函数, 就可以在整个系统中使用, 无需担心脚本是不是在 PATH 环境变量里.
17.7.1 在命令行上创建函数
单行方式定义函数:
1 | |
在命令行上定义函数时, 必须在每条命令之后加分号, 这样 shell 才知道在哪里是命令的起止.
多行方式定义:
1 | |
在函数的尾部使用花括号, shell 就会知道你已经完成了函数的定义.
如果你起了一个和内建函数或另一个函数相同的名字, 函数将会覆盖原来的命令.
17.7.2 在 .bashrc 文件中定义函数
在命令行上直接定义 shell 函数的明显缺点是退出 shell 时, 函数就消失了.
只要是在 shell 脚本中, 都可以用 source 命令来添加库文件.
17.8 实例
17.8.1 下载及安装
第18章 图形化桌面中的脚本编程
18.1 创建文本菜单
创建交互式 shell 脚本最常用的方法是使用菜单.
通常菜单脚本会清空显示区域, 然后显示可用的选项列表.
shell 脚本菜单的核心是 case 命令.
18.1.1 创建菜单布局
在创建菜单之前, 通常要先清空显示器上已有的内容, 这样就能在干净的环境中显示菜单.
在 echo 中使用非打印字符, 必须用 -e 选项:
1 | |
创建菜单的最后一步是获取用户输入, 使用 read 命令.
第19章 初识 sed 和 gawk
19.1 文本处理
19.1.1 sed 编辑器
sed 编辑器被称作流编辑器 (stream editor), 和交互式编辑器 (如 vim) 恰好相反.
sed 编辑器的操作:
- 一次从输入中读取一行数据
- 根据所提供的编辑器命令匹配数据
- 按照命令修改流中的数据
- 将新的数据输出到 STDOUT
命令格式:
1 | |
可用选项:
-e script,--express, 在处理输入时,将 script 中指定的命令添加到已有的命令中-f file在处理输入时,将 file 中指定的命令添加到已有的命令中-n,--quiet, 不产生命令输出,使用 print 命令来完成输出
sed 编辑器并不会修改文本文件的数据,它只会将修改后的数据发送到 STDOUT.
替换命令, 如:
1 | |
执行多个命令
执行多个命令时使用 -e 选项:
1 | |
(就是相当于运行几次 shell 命令)
多行命令
1 | |
从文件中获取命令
每个命令占一行,可以给文件添加后缀 .sed
19.1.2 gawk 程序
在所有的发行版中都没有默认安装 gawk 程序。
gawk 是原始 awk 的 GNU 版本。
gawk 提供了一种编程语言。
基本格式:
1 | |
可用选项:
-F FS, 指定行中划分数据字段的字段分隔符-f file, 从指定的文件中读取程序-v var=value, 定义 gawk 程序中的一个变量及其默认值-mf N, 指定要处理文件中的最大字段数-mr N, 指定数据文件中的最大数据行数-W keyword, 指定 gawk 中兼容模式或警告等级
gawk 的脚本用一对花括号来定义,必须把脚本命令放在一对花括号中 {}.
gawk 命令行假定脚本是单个文本字符串, 因此还需要把脚本放到单引号中:
1 | |
gawk 会从 STDIN 等待输入数据。
gawk 会对数据中的每行文本执行程序.
使用 Ctrl + D 终止程序.
使用数据字段变量
gawk 会给一行中的每个数据元素分配一个变量, 默认为:
$0, 代表整个文本行$1, 代表文本行中的第1个数据字段$2, 代表文本行中的第2个数据字段$n, 代表文本行中的第n个数据字段
在文本行中,每个数据字段都是通过字段分隔符划分的。默认为任意的空白字符.
在程序脚本中使用多个命令
使用分号 ; 分隔.
1 | |
一次一行:
1 | |
从文件中读取程序
1 | |
脚本文件中一条命令一行,不需要分号,但需要一对花括号.
在读取数据前运行脚本
gawk 允许指定程序脚本何时运行。
BEGIN 关键词,让程序在读取数据前运行脚本
1 | |
在处理数据后运行脚本
1 | |
19.2 sed 编辑器基础
19.2.1 更多的替换选项
替换标记
替换命令在替换多行文本时能够正常工作,但默认情况下它只替换每行中出现的第一处.
四种替换标签 (substitution flag):
- 数字,表明新文本将替换地挤出模式匹配的地方
- g, 表明新文本将会替换所有匹配的文本
- p, 表明输出修改过的行, 通常和
-n选项一起用 - w file, 将替换结果写到文件中这里的
1
$ sed 's/test/trial/w test.txt' data.txttest.txt是指定的用来保存的文件.
替换字符
sed 允许选择其他字符作为替换命令中的分隔符:
1 | |
这里用 ! 作为分隔符.
19.2.2 使用地址
使用行寻址 (line addressing), 将命令作用于特定行或某些行.
两种形式:
- 以数字形式表示行区间
- 用文本模式来过滤出行
格式均为:
1 | |
或:
1 | |
sed 编辑器会将指定的每条命令作用到匹配指定地址的行上.
数字形式的行寻址
可以是行号,也可以是区间:
1 | |
美元符 $ 是特殊地址,表示最后一行.
使用文本模式过滤器
格式为:
1 | |
必须用正斜线 / 将指定的 pattern 封起来,sed 编辑器会将命令作用到包含指定文本模式的行上.
如:
1 | |
在前面的文本模式中可以使用正则表达式.
命令组合
在单行执行多条命令:
1 | |
19.2.3 删除行
删除命令 d, 它会删除匹配指定寻址模式的所有行。
删除所有行:
1 | |
指定行号:
1 | |
指定区间:
1 | |
使用文本模式:
1 | |
使用两个文本模式删除某个区间,第一个文本模式会打开”删除”功能,第二个文本模式匹配结束后会关闭”删除”功能:
1 | |
19.2.4 插入和附加文本
- 插入 (insert) 命令 (i) 会在指定行前增加一个新行
- 附加 (append) 命令 (a) 会在指定行后增加一个新行
格式:注意这里是反斜线.1
$ sed '[address]command\ new_line_contents'
如:
1 | |
这样写更清晰:
1 | |
19.2.5 修改行
修改 (change) 命令允许修改数据流中整行文本的内容,其跟插入和附加命令的工作机制一样.
1 | |
也可以用文本模式寻址:
1 | |
若用区间会出问题:
1 | |
其会把 2,3 区间的行改为一行.
19.2.6 转换命令
转换 (transform) 命令 (y) 是唯一可以处理单个字符的 sed 编辑器命令。
格式:
1 | |
不要把 inchars 和 outchars 看做一个单词,应为一个个字符,其映射为一一对应,个数不一致会报错:
1 | |
文件里面所有的 1 会被替换为 4.
19.2.7 回顾打印
用于打印数据流中的信息:
- p命令用来打印文本行
- 等号 (=) 用来打印行号
- 1 (小写的L) 用来列出行
打印行
打印指定行地址的行:
1 | |
打印包含文本模式匹配上的行:
1 | |
打印行号
使用 =:
1 | |
sed 在实际文本出现之前打印出行号。
1 | |
列出行
列出 (list) 命令 (l) 可以打印数据流中的文本和不可打印的 ASCII 字符。
任何不可打印字符要么在其八进制值前加一个反斜线,要么使用 C 语言风格的命名法, 如 \t.
1 | |
19.2.8 使用 sed 处理文件
写入文件
1 | |
从文件读取数据
读取 (read) 命令 (r) 允许将一个独立文件中的数据插入到数据流中。
格式:
1 | |
sed 编辑器会将文件中的文本插入到指定地址之后.
1 | |
前面的文本模式对后面的命令都起效果.
第20章 正则表达式
20.1 什么是正则表达式
20.1.1 定义
正则表达式是你所定义的模式模板 (pattern template), Linux 工具可以用它来过滤文本.
20.1.2 正则表达式的类型
正则表达式引擎是一套底层软件, 负责解释正则表达式模式并使用这些模式进行文本匹配.
sed 编辑器只符合 BRE (Basic Regular Expression) 引擎规范的子集.
gawk 程序用 ERE (Extended Regular Expression) 引擎来处理它的正则表达式.
## 20.2 定义 BRE 模式
可使用的模式包括:
- ^ $ . [] *
### 20.2.2 特殊字符
正则表达式识别的特殊字符包括:
1
.*^${}\+?|()
### 20.2.8 特殊的字符组
BRE 的特殊的字符组:
- [[:alpha:]], 匹配任意字母字符
- [[:alnum:]], 匹配匹配任意字母和数字字符
- [[:blank:]], 匹配空格或制表符
- [[:digit:]], 匹配 0~9 之间的数字
- [[:lower:]], 匹配小写字母
- [[:print:]], 匹配任意可打印字符
- [[:punct:]], 匹配标点符号
- [[:space:]], 匹配任意标点符号
- [[:upper:]], 匹配大写字符
## 20.3 扩展正则表达式
可使用的包括:
- ? + {} | ()
1 | |
20.3.3 使用花括号
默认情况下 gawk 不会识别正则表达式间隔 (即指定范围), 需指定 --re-interval 命令行选项.
第21章 sed 进阶
21.1 多行命令
三个可用来处理多行文本的特殊命令:
- N : 将数据流中的下一行加进来创建一个多行组 (multiline group) 来处理
- D : 删除多行组中的一行
- P : 打印多行组中的一行
21.1.1 next 命令
单行的 next 命令
小写的 n.
也就是说, 先找到一行, 然后在其下一行执行命令列表. 之后也是先找, 然后再到下一行执行.
合并文本行
单行 next 命令会将数据流中的下一行文本行移动到 sed 编辑器的工作空间 (称为模式空间), 多行版本的 next 命令 (用大写 N) 会将下一文本行添加到模式空间中已有的文本后.
虽然文本还是用换行符分隔, 但 sed 编辑器现在会将两行文本当成一行来处理.
在处理完一个模式空间里的文本后, 下一个匹配的行是模式空间之外的行.
大概是这样, 有一个文件有四行文本:
1 | |
可以看作:
1 | |
命令为:
1 | |
相当于是先变成这样:
1 | |
然后再对 first 这一行, 将第一个 \n 转换成空格. 这就体现出合并.
要注意 N 命令处理最后一行时的问题, 因为是最后一行, 没有下一行可以合并到模式空间, N 命令会叫 sed 编辑器停止.
21.1.2 多行删除命令
d 命令是删除一行, 而不是一段文本. 和 N 命令配合时, 会将模式空间中的都删掉.
D 命令是多行删除命令, 其只删除模式空间中的第一行. 该命令会删除到换行符 (含换行符) 为止的所有字符.
21.1.3 多行打印命令
P 命令是多行打印命令, 它只打印模式空间中的第一行. 这包括模式空间中直到换行符为止的所有的字符.
21.2 保持空间
模式空间 (pattern space) 是一块活跃的缓冲区.
sed 编辑器有另一块称作保持空间 (hold space) 的缓冲区域.
在处理 pattern space 中的某些行时, 可以用 hold space 来临时保存一些行.
有 5 条命令可用来操作 hold space:
h, 将 pattern space 复制到 hold spaceH, 将 pattern space 附加到 hold spaceg, 将 hold space 复制到 pattern spaceG, 将 hold space 附加到 pattern spacex, 交换 pattern space 和 hold space 的内容
通常, 在使用 h 或 H 命令将字符串移动到 hold space 后, 最终还要用 g, G 或 x 命令将保存的字符串移回模式空间.
复制到, 意思就是会替换掉原本的内容.
21.3 排除命令
! 命令作为排除 (negate) 命令, 会让原本会其作用的命令起相反作用.
如:
1 | |
会将不包含 head 单词的行打印出来.
$ 表示的是特殊地址.
另一个例子:
1 | |
会对除最后一行的其他行执行 N 命令.
打印并不会移动缓冲区中的内容.
21.4 改变流
通常, sed 编辑器会从脚本的顶部开始, 一直执行到脚本的结尾 (D 命令除外, 它会强制 sed 编辑器返回到脚本的顶部, 而不读取新的行, 毕竟已经删除了一行了, 不可能对删除的行执行剩下的命令).
21.4.1 分支
分支 (branch) 命令 b 的格式:
1 | |
address 参数决定了哪些行的数据会触发分支命令.
label 参数定义了要跳转的位置, 如果没有加 label 参数, 跳转命令会跳转到脚本的结尾.
也就是说, 可以让某些行跳过某些命令而不执行.
标号以冒号开始, 最多可以是 7 个字符的长度. 要指定标签, 将它加到 b 命令后即可.
1 | |
达成循环效果:
1 | |
注意要防止无限循环.
感觉和汇编的 jmp 指令类似.
21.4.2 测试
测试 (test) 命令 t, 也用来改变 sed 编辑器脚本的执行流程.
t 命令根据替换命令的结果跳转到某个标签, 而不是根据地址进行跳转.
格式:
1 | |
和分支命令一样, 在没有指定标签的情况下, 如果测试成功, sed 回调转到脚本的结尾.
t 命令提供了对数据流中的文本执行基本的 if-then 命令的一个低成本办法:
1 | |
这个例子为, 如果第一个替换执行了, 就不会执行第二个.
可以用测试命令来结束循环.
21.5 模式代替
21.5.1 & 符号
& 符号可以用来代替命令中的匹配的模式.
1 | |
匹配到了 cat, 那么 & 的值为 cat, 匹配到后面的 hat, 则 & 的值为 hat.
21.5.2 代替单独的单词
sed 编辑器用圆括号来定义替换模式中的子模式.
替代字符由反斜线和数字组成, 数字表明子模式的位置, 如 \1, \2.
在替换命令中使用圆括号时, 必须用转移字符将它们标示为分组字符而不是普通的圆括号, 这有点反常:
1 | |
正则表达式的 * 放在文本的后面.
21.6 在脚本中使用 sed
21.6.1 使用包装脚本
在 shell 脚本中, 可以将普通的 shell 变量及参数和 sed 编辑器脚本一起使用:
1 | |
这个把命令行的第一个参数 (这里可以是文件名) 当成 sed 的输入. 这里的 $p 的含义是, 只有最后一行才打印. p 是一个动作.
21.6.2 重定向 sed 的输出
默认情况下, sed 编辑器会将脚本的结果输出到 STDOUT 上, 可以在 shell 脚本中使用各种标准方法对 sed 编辑器的输出进行重定向.
如用 $() 重定向到变量中.
21.7 创建 sed 实用工具
21.7.1 加倍行间距
保持空间的默认值为一个空行.
21.7.2 对可能含有空白行的文件加倍行间距
先删除所有的空白行, 然后用 G 命令在所有行后插入新的空白行.
21.7.3 给文件中的行编号
在获得等号的输出后, 可以通过管道将输出传给另一个 sed 编辑器脚本, 它会使用 N 命令来合并这两行, 还需要用替换命令将换行符更换成空格或制表符.
21.7.4 打印末尾行
创建滚动窗口. 通过循环使用 N 和 D 命令, 可以做到, 向模式空间的文本行块增加新行的同时删除旧行.
q (quit) 退出命令会停止循环.
21.7.5 删除行
选择性的删除数据中不需要的空白行.
区间地址, 如 /./,/^$/ 两个 pattern 用 , 分隔, 区间的开始是 /./ 匹配任意的一个字符, 结尾是 /^$/ 匹配一个空行.
第22章 gawk 进阶
gawk 同样不会直接修改文件.
22.1 使用变量
两种类型:
- 内建变量
- 自定义变量
22.1.1 内建变量
字段和分割符变量
数据字段变量. 使用 $ 来引用, 如 $1.
默认情况下, 字段分割符是一个空白字符.
| 变量 | 描述 |
|---|---|
| FIELDWIDTHS | 由空格分隔的一列数字, 定义了每个数据字段确切宽度 |
| FS | 输入字段分隔符, 默认为空格 |
| RS | 输入记录分隔符, 默认为换行符 |
| OFS | 输出字段分隔符号, 默认为空格 |
| ORS | 输出记录分隔符号, 默认为换行符 |
F 指 Field, 字段, 一行中的一部分 (不一定).R 指 Record, 记录, 指一行 (不一定).
Field 和 Record 都看你怎么去分割.
这里的 O 就是 Output.
一旦设置了 FIELDWIDTHS, gawk 就会忽略 FS 变量, 并根据提供的字段宽度来计算字段.
一旦设定了 FIELDWIDTHS 变量的值, 就不能再改变了.
示例程序:
1 | |
数据变量

gawk 并不会将程序脚本当成命令参数的一部分.
如:
1 | |
ARGC 变量表明命令行上有两个参数, 这包括 gawk 命令和 data1 参数, 中间的 BEGIN{print ARGC,ARGV[1]} 不算. ARGV 数组从索引 0 开始, 代表的是命令 (即 gawk). 第一个数组值是 gawk 命令后的第一个命令行参数.
跟 shell 变量不同, 在脚本中引用 gawk 变量时, 变量名前不加美元符.
ENVIRON (environment) 变量使用关联数组 (即字典) 来提取环境变量:
1 | |
可以用这种方法来提取任何环境变量的值.
NF (Number of Field) 变量可以让你在不知道具体位置的情况下指定记录中的最后一个数据字段:
1 | |
注意 FNR 和 NR 的区别, FNR 表示当前数据文件中已处理的记录数, NR 变量含有已处理过的记录总数.
在 shell 脚本中使用 gawk 时, 应该将不同的 gawk 命令放到不同的行, 这样容易理解和阅读.
可将 gawk 脚本放到一个单独的文件中, 并用 -f 参数来在 shell 脚本中引用.
22.1.2 自定义变量
变量名可以是任意数目的字母, 数字和下划线, 但不能以数字开头. 区分大小写.
1. 在脚本中给变量赋值
赋值语句可以包含数学算式来处理数字值.
1 | |
求余符号为 %, 幂运算为 ^ 或 **
2. 在命令行上给变量赋值
1 | |
此方法的缺点, 设置的变量值在代码的 BEGIN 部分不可用.
使用 -v 命令行参数解决. 其允许在 BEGIN 代码之前设置变量, 在命令行上, -v 命令行参数必须放在脚本代码之前:
1 | |
22.2 处理数组
gawk 使用关联数组 (字典) 提供数组功能.
22.2.1 定义数组变量
格式:
1 | |
如:
1 | |
22.2.2 遍历数组变量
关联数组变量的问题在于你可能无法知晓索引值:
1 | |
这个 for 语句会在每次循环时将关联数组 array 的下一个索引值赋给变量 var, 然后执行一遍 statements.
如:
1 | |
顺序是随机的.
22.2.3 删除数组变量
需要用:
1 | |
会删除索引和相关的数据元素值.
22.3 使用模式
22.3.1 正则表达式
在使用正则表达式时, 正则表达式必须出现在它要控制的程序脚本的左花括号前.
1 | |
gawk 程序会用正则表达式对记录中所有的数据字段进行匹配, 包括字段分隔符.
22.3.2 匹配操作符
matching operator 允许将正则表达式限定在记录中的特定数据字段. 匹配操作符是 ~.
1 | |
示例:
1 | |
先在 $1 (即第一个数据字段中) 查找文本 rich, 如果找到了这个模式, 它会打印该记录的第一个 ($1) 和最后一个数据字段 ($NF).
用 ! 符号排除正则表达式的匹配:
1 | |
如:
1 | |
22.3.3 数学表达式
显示所有属于 root 用户组 (组 ID 为 0) 的系统用户:
1 | |
$4 为记录的第四个字段.
可以使用任何常见的数学比较表达式, 如:
x == yx <= yx < yx >= yx > y
也可以对数据文本使用表达式, 但是必须完全匹配:
1 | |
22.4 结构化命令
22.4.1 if 语句
格式:
1 | |
如果要在 if 语句中执行多条语句, 就必须用花括号将它们括起来:
1 | |
gawk 的 if 语句也支持 else 子句.
可以在单行上使用 else 子句, 但必须在 if 语句部分之后使用分号:
1 | |
22.4.2 while 语句
1 | |
gawk 编程语言支持在 while 循环中使用 break 语句和 continue 语句.
22.4.3 do-while 语句
1 | |
这种格式保证了语句会在条件被求值之前至少执行一次.
22.4.4 for 语句
gawk 编程语言支持 C 风格的 for 循环:
1 | |
也有 i++, total += $1.
22.5 格式化打印
printf 命令, 和 C 中用发一致:
1 | |
格式化指定符格式:
1 | |
如:
三种修饰符进一步控制输出:
- width: 指定输出字段的最小宽度
- prec: 指定浮点数中小数点后面位数, 或者文本字符串中显示的最大字符数
-(减号): 指明采用左对齐
使用起来仍然是 %16.1f 这种.
22.6 内建函数
22.6.1 数学函数
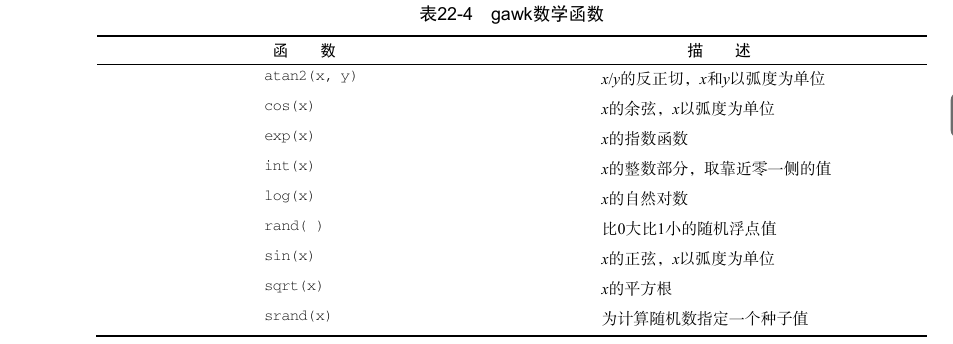
int() 会生成一个值的整数部分, 其为该值与 0 之间最接近该值的整数.
产生 0~10 之间的随机整数值:
1 | |
除了标准数学函数外, gawk 还支持一些按位操作数据的函数:
22.6.2 字符串函数


22.6.3 时间函数

22.7 自定义函数
22.7.1 定义函数
使用 function 关键词:
1 | |
函数还能用 return 语句返回值:
1 | |
22.7.2 使用自定义函数
在定义函数时, 它必须出现在所有代码块之前 (包括 BEGIN 代码块):
22.7.3 创建函数库
创建一个含有 gawk 程序的文件, 然后在命令行上用 -f 参数指定库文件和程序文件.
1 | |
22.8 实例
第23章 使用其他 shell
23.4 zsh shell
zsh 提供了一组核心内建命令, 并提供了添加额外命令模块 (command module) 的能力, 每个命令模块都为特定场景提供了另外一组内建命令.