Perl-进阶-Notes
第一章 简介
申请 PAUSE 账户, 此链接
使用 use 指定版本时, 小数点之后需要有三个数字, 如:
1 | |
也可以使用两个小数点的形式:
1 | |
or:
1 | |
第二章 使用模块
CPAN (Comprehensice Perl Archive Network). 有三个相关页面:
2.1 标准发行版
使用 Module::CoreList 模块可以查看不同 Perl 版本中自带的模块的信息.
Perl 安装时自带的模块被称为 “核心模块”, 或 “标准发行版”.
2.2 探讨 CPAN
介绍了很多网站, 具体看书.
2.3 使用模块
可以访问, 此网站, 以 HTML 格式或者 PDF 格式读取 Perl 一些版本的文档.
或者直接用 perldoc 命令直接查看.
2.4 功能接口
选择需要导入的内容
在模块名之后指定一个子例程列表, 称导入列表:
1 | |
更常见的写法:
1 | |
即使导入列表中仅有一项, 我们仍然倾向于将该项写入 qw() 列表, 使程序一致性更好并且易于维护.
在调用子例程时, 我们不需要在前面添加 “&” 符号, 这是因为编译器已经通过 use 语句知道子例程的名称.
2.5 面向对象的接口
1 | |
调用 File::Spec 的 catfile 类方法. 该方法为本地操作系统创建一个合适的路径, 并且返回单个字符串.
2.5.1 一个更典型的面向对象模块: Math::BigInt
1 | |
new 关键词用来创建对象.
2.5.2 更佳的模块输出
使用 Spreadsheet::WriteExcel 模块.
2.6 核心模块的内容
关于 Module::CoreList 模块, 见书.
2.7 Perl 综合典藏网
2.8 通过 CPAN 安装模块
使用 Perl 自带的 cpan 程序, 只需告诉 cpan 需要安装的模块的名称.
如:
1 | |
若不带参数, 会启动 CPAN.pm 中的交互 shell 模式:
1 | |
可使用:
1 | |
查阅.
另一个 CPANPLUS 模块.
2.8.1 CPANminux
cpanm 工具.
2.8.2 手动安装模块
如:
1 | |
如果找到一个名为 Makefile.PL 的文件, 就运行这一系列编译, 测试和最终安装源代码的命令:
1 | |
可通过配置 INSTALL_BASE 参数, 将该模块安装到其他路径. 可通过 perl -V 查看默认库目录等设定.
1 | |
为了使 Perl 能够在以上目录中查找所安装的模块, 可以设置 PERL5LIB 环境变量.
1 | |
也可以使用 lib 编译指令将模块的安装目录添加到模块的搜索路径中.
1 | |
如果在模块的安装目录下找到的是 Build.PL 文件而不是 Makefile.PL:
1 | |
使用的是 install_base 参数.
2.9 适时设定路径
Perl 会浏览 @INC (include) 数组中的目录元素以查找模块
在 use 执行前修改 @INC 数组的内容, 添加 BEGIN 块:
1 | |
可用 lib 代替:
1 | |
lib 编译指令获取一个或者多个参数, 并且将它们添加到 @INC 数组的起始部分.
use lib 后面只是模块所在的目录的路径, 而不是模块的路径.
use lib 在编译时运行.
FindBin 模块. 该模块查找脚本目录的完整路径, $BIN 变量是对应脚本所在目录的路径.
1 | |
2.10 在程序外部设定路径
2.10.1 使用 PERL5LIB 扩展 @INC
PERL5LIB 变量能够在类 UNIX 系统中包含由冒号分割的多个目录.
2.10.2 在命令行扩展 @INC 目录
使用一个或多个 -I 选项直接调用 perl:
1 | |
2.11 local: lib
默认情况下, CPAN 工具将新模块安装到与 perl 相同的目录.
local::lib 模块设定多种环境变量, 其影响 CPAN 客户端安装模块的位置和 Perl 程序查找所安装的模块的位置.
1 | |
安装 local::lib 模块.
1 | |
可以在 CPAN 工具中使用 -I 选项来使用 local::lib 模块.
1 | |
其会查找你是否有默认目录的写入权限, 如果没有, 则会自动启用 local::lib 模块.
若要明确使用:
1 | |
在程序中使用 local::lib 模块, 程序就知道在何处查找我们安装的模块.
还可这样处理任何路径:
1 | |
第3章 中级基础
3.1 列表操作符
3.1.1 使用 grep 表达式
可匹配正则表达式:
1 | |
如果测试过于复杂, 就可以将其隐藏在一个子例程中:
1 | |
另一种写法为:
1 | |
这里的代码块实际上是一个匿名子例程.
能够引入作用域限于 “块” 的变量, 即使用 my.
3.1.2 使用 map 转换列表
可以每个输入产生两个输出:
1 | |
可直接使用 map 表达式生成散列:
1 | |
可以为每个输入项生成不同的输出项:
1 | |
split // 就是直接把输入拆开.
如果一个特定调用的结果是空列表, map 表达式就将这个空结果连接到更大的列表中, 不为列表添加任何元素:
1 | |
能够用 map 表达式和 grep 表达式做的所有事情, 也能够使用显示的 foreach 循环完成.
3.2 使用 eval 捕获错误
eval 表达式是 Perl 的首选异常机制.
最常见的是在 eval 语句块执行完之后立即检查 $@, 该特殊变量为空则意味着没有错误.
1 | |
eval 语句块后的分号是必须的, eval 是一个术语, 而不是控制结构.
块中的代码运行失败, 在标量上下文中返回 undef, 在列表上下文中返回空列表. 成功则有正常的返回值.
eval 不捕获警告, 语法错误, 和 perl 自己中断执行的错误.
3.3 用 eval 语句块动态编译代码
eval 语句块的第二种形式: 参数是字符串表达式而不是代码块. 在运行时通过字符串的方式编译和执行代码. 但是不建议对字符串使用 eval 语句块.
1 | |
Perl 在词法上下文中执行 eval 语句块前后的代码, eval 语句块的结果即为最后一个表达式的值.
如果 eval 语句块不能够正确编译并且不能正确运行我们传递的 Perl 代码, 同样设置 $@ 变量.
3.4 使用 do 语句块
do 语句执行的结果同样是最后一个表达式的值. do 语句可以把一组语句聚集为单个表达式.
如, 将:
1 | |
用 do 表达式写为:
1 | |
do 语句适合创建一个操作的作用域
1 | |
同样可以向 do 语句块提供字符串的形式, 其会尝试通过该字符串名称加载, 编译文件:
1 | |
内置的 require 同样也可用于加载模块:
1 | |
use 语句实际上是一个 BEGIN 块中 require 语句和调用类导入的内容:
1 | |
习题
判断某个条件错误时执行某个操作使用 unless 比较合适.
从外部文件或 STDIN 获取输入时, 最好用 chomp 去除换行符.
第4章 引用简介
4.1 在多个数组上完成相同的任务
Perl 的参数列表是 @_ 数组. 传递参数同样通过括号.
PeGS: Perl 图形结构
PeGS (Perl Graphical Structure). 是 Perl 数据结构的图形表示方式.
大多数 PeGS 图由两部分组成: 变量名称和该变量引用的数据.
4.3 对数组取引用
反斜线 \ 用于 “取引用” 操作.
如, 放在数组名称之前 \@skipper 就得到该数组的引用. 和 C 中的指针有些区别, 引用指向整个数组, 而不是数组本身的第一个元素的地址.
引用能够作为数组或者散列的元素, 也能直接放入普通标量变量中:
1 | |
引用同样是指向地址, 引用的数值形式是 @skipper 数组在内部数据结构中唯一的内存地址, 该地址在数据的生存在周期内部都不会改变.
若是直接向子例程传递参数, 实际上是将参数都复制了一遍, 而使用引用则避免了这里的消耗.
4.4 对数组引用进行解引用操作
解引用实际上就是取地址上的值.
可以将数组的任意引用放入大括号中, 用于替换数组名称, 最后以i一个访问原始数组的方法作为结束 (也就是用大括号 “{}” 来解引用):
1 | |
以下两种方法都指向数组的第二个元素:
1 | |
4.5 去除大括号
如果只是一个简单的标量值, 那么也可删除第一组大括号.
见书.
4.6 修改数组
修改解引用的数组就是修改原始数组.
4.7 嵌套的数据结构
4.8 用箭头简化嵌套元素的引用
在编写 ${DUMMY}[$y] 的任何地方, 都可以使用 DUMMY->[$y] 这种方式代替.(引用位于箭头之前)
通过在表达式后面用一个箭头和一个带方括号的下标定义数组引用, 就可以选取数组中一个特定的元素.
如:
1 | |
另一条规则: 如果箭头位于 “下标类的符号” 之间, 也可以删除这些箭头:
例如(含义为, 先解引用 all_with_names 这个数组的第三个元素, 再…):
1 | |
可以表达为:
1 | |
基本上是有几个 [] 就是几重数组.
4.9 散列的引用
同样使用 \ 反斜线作为 “取引用” 操作符.
同样有大括号, 箭头形式.
对于数组切片或散列切片, 没有带箭头 (->) 的快捷方式.
如:
1 | |
4.10 检查引用类型
开始使用和传递引用时, 必须确保知道正在使用哪种类型的引用.
最简单的方式是使用 ref 函数.
1 | |
ref 的返回值是类型名, 如 HASH.
constant 变量感觉类似于 C 中的宏定义:
1 | |
Scalar::Util 模块中的 reftype 函数也能完成 ref 函数的任务.
可以使用 eval 检查:
1 | |
第5章 引用和作用域
能够像标量一样复制并且传递引用.
5.1 关于数据引用的更多信息
Perl 通过一个叫做 “引用计数” 的机制追踪有多少中访问数据的方法.
有了初始名称, 引用计数就为 1.
可以随意添加和删除引用, 并且只要引用计数没有减少到 0. Perl 就将在内存中保存该数组.
销毁引用, 可以把 undef 赋给该变量:
1 | |
特殊情况下, 保存在子例程的私有 (词法) 变量中的引用, 将会在子例程的结尾销毁.
仅当所有引用销毁时, Perl 才会回收数组占用的内存.
5.2 如果它曾是变量名将会怎样
5.3 引用计数和嵌套数据结构
删除数据树顶端的节点通常就意味着删除该数据树包含的所有数据.
Perl 会保证, 如果我们仍然拥有一个指向数据的引用, 就将仍然拥有该数据.
5.4 当引用计数出现问题时
当数据结构中的一部分以循环的方式指向数据结构的其他部分时, 就会出现问题.
5.5 直接创建匿名数组
使用方括号:
1 | |
取方括号内的值 (在列表上下文中求值), 为这些元素创建一个新的匿名数组, 并且返回该数组的引用.
使用方括号匿名数组构造函数得到的结果是一个数组引用, 该引用适用于标量变量适用的所有场合.
创建更大的列表:
1 | |
使用匿名数组的好处在于不用记忆中间名称.
可以用空的匿名数组构造器函数表示空的匿名数组引用.
1 | |
5.6 创建匿名散列
大括号 {} 是匿名散列构造函数.
1 | |
注意, 当列表末尾的元素并非紧跟着右花括号, 方括号或小括号时, 可以以逗号结尾.
1 | |
向编译器说明我们想要一个匿名散列构造函数, 就在左大括号之前放置一个加号:
1 | |
如果想得到一个代码块, 就在语句块开始处放置一个分号:
1 | |
5.7 自动带入
5.8 自动带入和散列
自动带入的一个便捷之处在于典型的数据压缩任务.
1 | |
此处两个大括号间有隐式的箭头.
第6章 操作复杂的数据结构
6.1 使用调试器查看复杂的数据
最简单的一种是在命令行条件下调用 perl 并带上 -d 参数.
每个新发布的调试器都与之前发布的调试器在工作方式上略有不同.
有任何问题都可以通过输入 h 或者查看 perldebug 文档.
调试器会在执行前显示每一行正在调试的代码.
s 命令将单步执行程序.
x 命令显示存储在列表中的所有值.
6.2 使用 Data::Dumper 模块查看复杂的数据
Data::Dumper 将 Perl 的数据结构显示为 Perl 代码.
1 | |
Data::Dumper 模块定义的 Dumper 子例程类似与调试器中的 x 命令. 其与 x 命令的区别在于, Dumper 生成的字符串是 Perl 代码.
其他形式的转储程序
Data::Dump 模块有一个叫做 dump 的子例程, 与 Data::Dumper 模块的用法一致.
1 | |
1 | |
Data::Printer 模块的 p 子例程不需要一个引用作为参数:
1 | |
6.3 数据编组
能够将 Data::Dumper 模块 Dumper 子进程的输出放入一个文件中, 然后另一个程序加载该文件.
6.3.1 使用 Storable 模块对复杂数据排序
编组数据: 将复杂数据转换成一种能够作为字节流写入文件的一种形式.
Perl 的 Storable 模块更适合编组数据.
Storable 生成更短小并且易于处理的文件.
freeze 子例程返回一个二进制字符串, 该字符串用于表述所需要输出的数据结构:
1 | |
6.3.2 YAML 模块
YAML (Yet Another Mark Language).
YAML 模块的工作方式与 Data::Dumper 模块相同.
1 | |
6.3.3 JSON 模块
JSON (JavaScript Object Notation).
JSON 模块有很多中创建输出的方法, 其中就包括 to_json:
1 | |
这里的 { pretty => 1 } 是使用属性.
可以从一个文件, Web 请求或者来自其他程序的输出获取 JSON 文本:
1 | |
6.4 使用 map 和 grep 操作符
6.5 应用一点间接方法
第7章 对子例程的引用
除了对标量, 数组和散列的引用, 也可以对一个子例程进行引用.k
7.1 对命名子例程的引用
对子例程 skipper_greets() 取引用, 前导字符 “&” 在这里是必须的, 但删除了其后的小括号.
1 | |
解引用同样是加大括号:
1 | |
同样, 如果大括号里的值是简单的标量变量, 大括号可以删除:
1 | |
也可以转换成带箭头的形式:
1 | |
迭代调用所有子例程:
1 | |
也就是说, 用子例程的引用的一个好处就是, 当子例程调用的参数相同时, 可以利用控制结构简化操作.
7.2 匿名子例程
匿名子例程看上去像是普通子例程, 只是在 sub 关键字和紧随的代码块之间没有名字, 最后有一个分号, 毕竟是一个赋值语句, 其返回一个子例程的引用:
1 | |
7.3 回调
File::Find 模块导出的 find 子例程, 用来以可移植的方式遍历给定文件系统的层次结构. 传递给 find 子例程两个参数: 第一个是对子例程的引用. 该子例程会从给定的起始目录开始, 通过递归搜索的方法, 找到其下的每个文件或目录, 执行子例程引用下的操作, 第二个表示目录开始点的字符串:
1 | |
改用匿名子例程的方式:
1 | |
7.4 闭包
还可以用 File::Find 来查找文件的一些其他属性.
$_ 中保存的是文件名, 而 File::Find::name 中保存的是相对于起始路径的文件名. 如, 若起始目录为 /usr, 查找的文件为 /usr/bin/perl, 那么 $_ 中的值为 perl 而 $File::Find::name 的值为 /bin/perl.
能够访问声明时就存在的所有词法变量的子例程叫做闭包. (也就是说变量是在子例程外面声明的).
从闭包内部访问变量能够确保只要子例程引用存在, 访问的变量就存在.
1 | |
7.5 从一个子例程返回另一个子例程
1 | |
7.6 作为输入参数的闭包变量
闭包变量也同样可以用于为子例程提供初始变量或者持续输入.
1 | |
7.7 闭包变量作为静态局部变量
命名子例程也可以是闭包.
如:
1 | |
子例程在作用域外仍将保持. 也就是说, 上面虽然是在一个代码块中, 外面的程序仍然能够使用这两个子例程.
1 | |
实测加上 BEGIN 结果也是一样的?
state 变量
Perl v5.10 版开始为子例程引入了另一种方法生成私有的, 持续的变量. (也就是说重复调用子例程时值不会丢失)
可以使用 state 语句在子例程内部声明变量.
1 | |
state 变量有一个限制, 仅能使用 state 语句初始化标量变量. 能够使用 state 语句声明任何类型的变量, 但是不能初始化它们.
7.8 查询我们自己的身份
Perl v5.16 版引入 __SUB__ 标记 (token), 返回一个指向当前子例程的引用.
1 | |
7.8.1 令人着迷的子例程
1 | |
这里每一个 when 中的第一个 ref 实际上是 ref $_.
7.8.2 转储闭包
Data::Dump::Streamer 模块是增强版的 Data::Dumper 模块.
1 | |
第8章 文件句柄引用
8.1 旧方法
8.2 改进的方法
从 Perl v5.6 开始, open 命令能够以普通的标量变量形式创建一个文件句柄的引用, 前提是只要该标量变量的值未定义.
1 | |
同样, 在 <> 中:
1 | |
8.3 指向字符串的文件句柄
从 Perl v5.6 开始, 能够打开一个标量引用形式的文件句柄, 而不是一个文件, 该文件句柄要么从该字符串读取要么向该字符串写入.
1 | |
逐行处理字符串
8.4 文件句柄集合
可以将文件句柄引用作为数组元素或者散列值存储.
当文件句柄超出其作用域时, 就会被自动关闭.
1 | |
8.5 IO::Handle 模块和其他相应的模块
在幕后, Perl 实际上使用 IO::Handle 模块实现文件句柄操作.
文件句柄量实际上是 IO::Handle 模块的对象.
1 | |
自 Perl v5.14 之后, 不必显式加载 IO::Handle 模块.
IO::Handle 包对于输入, 输出操作而言是基础类, 因此它能够处理很多事情, 而不仅仅是文件.
8.5.1 IO::File 模块
IO::File 模块是 IO::Handle 模块用于操作文件的子集, 该模块来自于 Perl 标准发行版.
1 | |
其返回一个文件句柄.
打开匿名的临时文件:
1 | |
可以显式调用 close 或 undef 命令操作文件句柄:
1 | |
如果将 undef 作为文件名, Perl v5.6 及后续版本能够打开一个匿名, 临时的文件:
1 | |
8.5.2 IO::Scalar 模块
若 Perl 的版本不能创建标量引用形式的文件句柄. 就可以使用 IO::Scalar 模块. 该模块不是 Perl 标准发行版的模块.
1 | |
8.5.3 IO::Tee 模块
其不是自带的模块.
将内容同时输出到多个地方, 使用 IO::Tea 模块.
当输出到达 IO::Tee 模块时, 它就能够同时流向两个 (甚至多个) 不同的管道.
1 | |
如果 IO::Tee 模块的第一个参数是 (随后的参数必须是输出文件句柄).
当 IO::Tee 模块从输入句柄读取一行数据时, 他就立即将该数据写入输出文件句柄.
1 | |
$read_fh 可能连接到一个套接字, 标量变量或者外部命令的输出.
8.5.4 IO::Pipe 模块
与 Shell 中的管道类似, 符号 | 之后的 $command 将会记录来自命令的输出, 然后通过管道传入程序. 具体见 learning perl.
使用 IO::Pipe 模块, 其自动处理 fork 命令和 exec 命令, 返回一个文件句柄, 可以从该文件句柄读取命令的输出:
1 | |
命令就写在 reader() 中.
写入:
1 | |
8.5.5 IO::Null 模块和 IO::Interactive 模块
使用 IO::Null 模块创建一个文件句柄用于丢弃所提供的内容, 如 /dev/null.
1 | |
如:
1 | |
8.6 目录句柄
与创建文件句柄引用的方式一致:
1 | |
目录句柄引用
自 v5.6 起, IO::Dir 模块就成为 Perl 标准发行版的一部分.
1 | |
第9章 正则表达式引用
9.1 正则表达式引用之前
用 eval 语句在匹配时捕获可能发生的错误:
1 | |
在尝试使用一个模式之前, 编写一个子例程测试该模式:
1 | |
但这样仍然不太好.
9.2 预编译模式
Perl v5.5 引入一个新的引用机制: qr// 操作符. 这里的预编译应该是说其产生的引用会在预编译时展开.
qr 是 regex quote.
提供一个编译完成的正则表达式的引用:
1 | |
在 perlop 文档中可查看 “引号和类引号操作符”.
分隔符可换 (qr//, 改为 qr() 之类的).
可以添加 options :
1 | |
9.2.1 正则表达式选项
特殊序列 (?flags:pattern) 允许在模式本身中指定修饰符 (也就是说不把标志写在末尾, 而是在正则表达式之中):
1 | |
分组;
1 | |
能够在标记之前添加一个 “-“, 从一部分模式中移除修饰符:
1 | |
同时添加和移除:
1 | |
9.2.2 应用正则表达式引用
直接插入:
1 | |
直接绑定:
1 | |
智能匹配:
1 | |
9.3 作为标量的正则表达式
可将其存储在数组和散列中, 作为参数传递给子例程.
使用 List::Util 模块中的 first 函数:
1 | |
9.4 建立正则表达式
将模式插入其他模式之中:
1 | |
9.5 创建正则表达式的模块
9.5.1 使用常见的模式
能够直接使用 Regexp::Common 模块提供的某个模式.
该模块导出一个叫做 $RE 的散列引用, 它以我们所需要的正则表达式引用作为其值:
1 | |
若查找 IPv4 地址, 能够使用该模块的 net 工具衍生出的一个模式:
1 | |
匹配数字:
1 | |
可查询 perltie 文档, 查看关于 tie 的信息.
具体看书.
9.5.2 组装正则表达式
Regexp::Assemble 模块可用于建立高效的则一匹配.
第10章 实用的引用技巧
注意 sort 函数对数字的排序, 其会按照字符串的顺序进行排序. 如, 任何以 3 开头的字符串都放置于 4 开头的字符串之前.
升序:
1 | |
降序:
1 | |
10.2 用索引排序
1 | |
也就是说利用索引排序 ($a 和 $b 的值为数组的索引), 结果仍然是按照 ASCII 的顺序.
$#input 表示数组的最有一个索引.
10.3 更为高效的排序
1 | |
10.4 施瓦茨变换
如这种结构:
1 | |
基本语法结构:
1 | |
10.5 使用施瓦茨变换实线多级排序
10.6 递归定义的数据
如:
1 | |
10.7 构建递归定义的数据
如:
1 | |
获取数据并形成结构:
1 | |
检查结果:
1 | |
10.8 显示递归定义的数据
10.9 避免递归
使用迭代解决问题.
第11章 构建更大型的程序
11.1 修改通用代码
大多数用 shift 来获取参数.
11.2 使用 eval 插入代码
将代码放入如 Navigation.pm 的独立文件中, 该文件由所需的多个子例程组成. (.pm 即 Perl Module)
用硬编码 (即直接将数据写到源代码中), 用 eval 的字符串形式 (可以理解为字符串被当作代码编译):
1 | |
11.3 使用 do 语句
1 | |
do 操作符的功能就像是把 Navigation.pm 的代码合并进当前程序中, 尽管导入的变量还在它自己的作用域语句块中. (即里面是它自己的作用域, 如 my 和 use 不会和主程序冲突);
11.4 使用 require 语句
require 可以追踪哪些文件已经导入, 然后仅导入一次.
特性:
- 导入文件中的任何语法错误都将终止程序, 所以不再需要很多
die $@ if $@ - 文件中的最后一个求值表达式必须返回一个真值
因此, 大多数用于 require 导入的文件中, 最后一行代码总有一个 1 (来确保最后的求值表达式为真).
11.5 命名空间冲突的问题
11.6 使用包作为命名空间分隔符
用 package 命令. (用在模块中, 而不是你要调用模块的文件)
1 | |
实际上是在这个模块中, 给大多数 (变量) 名称之前插入 Navigation:: 前缀. 这样用 require 导入就可以避免命名冲突.
包名应当以一个大写字母开头.
包名也可以为由双冒号分割的多个名称, 如 Minnow::Navigation.
11.7 Package 指令的作用域
所有 Perl 文件运行时就好象我们有一个 main 包定义在起始部分. 直到声明下一条包指令之前, 当前所有包指令仍然有效, 除非包指令在一个带大括号的作用域中. 在那种情况下, Perl 解释器会记住之前的包指令, 当带大括号的作用域结束时, 就还原之前的包指令:
1 | |
大多数库在文件的起始部分仅有一个包声明, 大多数程序把 main 包作为默认的包名.
不管当前包的定义如何, 一些名称总在 main 包中. (具体见书)
11.8 包和专门词汇
通过 my 关键词引入的变量不使用当前包作为前缀, 因为包变量总是全局变量 (词法变量对于程序的一部分而言通常是临时的并且可访问的)
our 关键词表明一个 package 中的变量前面可以不用加 package 名.
具体看:
1 | |
包语句块
可以使用语句块的语法:
1 | |
新的包语法允许指定一个版本:
1 | |
第12章 创建你自己的发行版
12.1 Perl 模块的两个构建系统
Perl 有两种常见的发行版构建系统:
- ExtUtils::Makemaker, 基于 make 构建, 使用一个叫做 Makefile.PL 的文件来控制构建过程
- Module::Build, 使用 Build.PL 文件
12.1.1 在 Makefile.PL 内部
可在 ExtUtils::Makemaker 模块的文档中了解配置细节.
PREREQ_PM 键的值,列出了在运行代码时需要的以来模块及其版本号, 当在这里列出以来的模块时,CPAN 客户端都能够自动获取,构建并且安装它们.
1 | |
指定模块的版本:
1 | |
另一个有用的设置 EXE_FILES 键, 在它对应的值里面列出发行版中包含的可安装程序:
1 | |
12.1.2 在 Build.PL 文件内部
Module::Build::API 的文档解释了有效键的所有信息.
12.2 我们的第一个发行版
12.2.1 h2xs 工具
h2xs 用来将 C 语言的 .h 头文件转换成 .xs 文件,作为连接 C 和 Perl 的胶水语言.
使用 -A 和 -X 参数来关闭 AUTOLOAD 和 XS 特性. 使用 -n 开关设置模块名称:
1 | |
这将创建一系列文件.
12.2.2 Module::Starter 模块
更加通用的做法是使用 Module::Starter 模块, 该模块并不包含在标准库中.
通过 module-starter 程序,可以设定我们的姓名和电子邮箱,这些信息将被插入相关文件合适的地方.
1 | |
默认情况下, module-starter 程序会创建一个带 Makefile.PL 的安装目录系统发行版.
如果享用 Module::Build 模块替代,使用 --builder 参数:
1 | |
module-starter 的配置文件位于 $HOME/.module-starter/config, 也可以设置 MODULE_STARTER_DIR 环境变量来指定包含 config 的目录名称.
在配置文件内部,可以列出用冒号分割的所有参数名称和值:
1 | |
之后只需要运行:
1 | |
就可以达到同样的效果.
12.2.3 定制模板
Module::Starter::Plugin 模块的文档展示了如何创建自己的插件.
对于真正复杂的模块创建,可以使用 Dist::Zilla 模块.
12.3 在你的发行版内部
运行构建脚本:
1 | |
Build.PL 会检查发行版,确保它所需要的所有文件是完整的,每个发行版将在 MANIFEST 文件记录检查的结果.
一旦 Build.PL 文件完成了检查,它将创建一个程序,其中包含 Perl 的设置,模块的路径和其他一些信息.
1 | |
其:
- 从 lib 目录将模块文件复制到构建库 blib 目录中 , 这是构建系统用来保存所有准备安装文件的位置
- Module::Build 模块将 Animal 模块内置的文档装换成 UNIX 系统中类似的手册页 (manpage), 然后放置到
blib/libdoc目录中.
测试命令:
1 | |
测试的脚本由之前 module-starter 命令创建于 t 目录中.
另一个测试参数 disttest, 用于发布发行版之前. 用来检查我们即将放入压缩包和发布的内容已经包含测试所需的所有信息:
1 | |
过程: Build 会为它即将创建的压缩包文件创建一个子目录,将 MANIFEST 中列出的所有文件复制进去,切换到子目录的位置,然后再次执行测试.
真正准备好发布发行版时,执行 dist 参数,MAINIFFEST 文件中列出的所有文件都将被重新组织.
12.3.1 META 文件
客户端可以根据 META.json 和 META.yml 文件的信息判断它需要做什么事情.
_require 字段列出安装环境需要满足的条件.
12.3.2 添加额外的模块
一开始酒吧多个模块文件放入一个发行版中:
1 | |
在创建发行版之后,还想往发行版中添加新的模块文件,使用 Module::Starter::AddModule 模块, 但这个模块需要安装好, 可以将 module-starter 的配置文件写为:
1 | |
用 module-starter 添加时需要用 --dist 参数指定添加到哪一个发行版,用 --module 参数指定要添加的模块:
1 | |
添加的模块也是一个新的模块,而不是 cpan 上已有的模块. 实际上就是添加模块的模板文件.
12.4 模块内部
Perl 有一个嵌入式的文档称为 Pod, 它是 Plain ol’Documentation 的简称. 可以在代码部分之间放置 Pod, 就是一些代码接着一些文档,再接着一些代码的格式.
可在 perlpod 和 perlpodspec 两个文档中参考 Pod 的文本格式规范.
12.5 老式文档
Perl 解析器会忽略文档部分.
perldoc 程序会忽略代码部分.
可以直接用 perldoc 来阅读 Pod 文档部分:
1 | |
默认情况下,perldoc 借助 nroff 命令.
可以用 pod2html 程序将 Pod 转换成 HTML 格式:
1 | |
12.5.1 段落的 Pod 命令
=headn 指定一个标题.
=head1 是一级标题.
=head2 是二级标题.
需要返回代码模式时,就以 =cut 语句结束.
1 | |
可以用 =over n 来创建列表, 列表的每个元素用 =item 来标记.
1 | |
使用 * 就会显示 *:
1 | |
12.5.2 Pod 段落
在文档中加入文本:
1 | |
12.5.3 Pod 格式标记

处理 UTF-8:
1 | |
12.5.4 检查 Pod 格式
可以用 podchecker 来检查 Pod 文档的语法是否正确:
1 | |
12.6 模块中的代码
按照惯例,Perl 模块使用包变量 $VERSION 来声明版本号.
1 | |
12.7 模块构建的总结
见书.
第13章 对象简介
仅在程序的长度超过 N 行后 OOP (Object Oriented Programming) 的益处才能会显露出来.
可查阅 《Object Oriented Perl》一书.
Perl 的对象架构是在包,子例程和引用的概念上建立的.
13.1 如果我们可以和动物对话……
13.2 介绍方法的调用箭头
类是一组拥有类似行为和特征的事物.
如:
1 | |
可以将类名放入变量中使用:
1 | |
13.3 方法调用的额外参数
两种形式:
1 | |
13.4 调用第二个方法进一步简化
这里调用的 sound 方法返回一个常量文本:
1 | |
使用 “继承” 来共享方法的定义.
13.5 关于 @ISA 的几个注意事项
@ISA 的读法是 is a.
Perl 解释器在 @ISA 中的查找是递归的,深度优先,并且从左到右进行.
当当前类中没有调用的方法时,Perl 解释器就会在 @ISA 数组中的类中查找.
两种使用方法:
1 | |
or:
1 | |
可以使用编译提示符 use parent:
1 | |
13.6 方法重写
直接改写即可,调用方法时若是在本类中找到了,就不会去 parent 中找.
应当使用继承的方式重用代码,而不是用复制和粘贴.
13.7 开始从不同的地方查找
13.8 使用 SUPER 的实现方法
1 | |
SUPER::speak 意味着应当在当前包的 @ISA 中查找 speak 方法,如果找到多个,就调用第一个.
13.9 要对 @_ 做些什么
13.10 我们在哪里
如:
1 | |
此时,Perl 隐式地将类名放置于参数列表之前:
1 | |
第14章 测试简介
14.2 Perl 的测试流程
Perl 测试惯例是在 Perl 程序所在的文件夹中建立一个文件夹,叫做 “测试文件”.
通用测试协议
通用测试协议 – Test Anywhere Protocol, TAP. 就是规范测试的输出.
测试通过,输出 ok 和一个测试编码.
1 | |
可以给测试附加一个标签,使我们知道通过了什么:
1 | |
测试没有通过,输出 not ok:
1 | |
现在 Perl 主要的测试模块: Test::More.
如使用 ok 子例程:
1 | |
tests => 1 明确声明只有一个测试。
如果不知道测试数量,就在测试代码末尾使用 done_testing:
1 | |
is 子例程,我们传入所拥有的值,所期望的值,和测试标签:
1 | |
还有 isnt, like, unlike, is_deeply 这些子例程.
14.3 测试的艺术
原则: 记住编程过程中曾经犯过的错误是很重要的.
一个测试示例
1 | |
用 eval 捕获得到的结果:
1 | |
14.4 测试用具
当我们运行测试的时候,调用了一个叫做测试用具的东西,它将查找所有测试程序, (以 .t 结尾的文件), 逐个运行它们,捕获输出,并提供结果的一个总体摘要.
Test::Harness 模块会搜集测试脚本,并运行它们,最后汇总结果.
14.5 标准测试
当使用module-starter(或者h2xs)程序创建我们自己的发行版时,就自动生成了一些初始测试脚本以及一些其他文件。按照惯例,测试文件位于t目录并以 .t扩展名结尾。
当运行测试程序时,构建程序将运行它在t目录中所查找到的每个测试文件:
1 | |
有些人吧作者测试目录设置成 xt, 以便与代码测试目录 t 分开.
在这些测试做任何事情之前,它们会检查那些需要完成工作的相依赖模块。如果没有,就将跳过这些相应的测试。
14.5.1 模块编译的检查
t/00-load.t 文件,这是运行的第一个测试文件,因为默认测试顺序是按照字典顺序执行
使用 blib 模块,其会搜索周围的目录,包括父目录, 用于将 blib 添加到 @INC 数组中:
1 | |
-T 参数是开启 “污染” 检查模式.
14.5.2 模板测试
t/boilerplate.t 文件.
我们不用保留 t/boilerplate.t 文件,一旦我们替换了占位符文本,就可以删除这个文件了.
14.5.3 测试 Pod
标准的 Pod 测试只关心两件事: 我们的 Pod 没有任何格式错误和我们已经为每个子例程编写了文档.
这些测试都是可选的,并且只有在安装了Test::Pod模块和Test::Pod::Coverage模块后才会运行。这些测试会自动查找所有模块文件并逐个进行测试,因此我们不用修改这些测试脚本。
如果我们还没有给新添加的子例程编写相应的文档,Pod覆盖测试就会无法通过.
要修复这个Pod测试,我们需要使用我们自己的方法中的文档替换存根文档中的信息。
14.6 添加第一个测试
添加自己的测试文件。
第15章 带数据的对象
15.1 马属于马类,各从其类是吗
1 | |
一个实例会有关联的属性,称为实例变量 (或叫成员变量).
在 Perl 中,实例必须是一个内置类型的引用.
1 | |
可以在 perldoc -f bless 中查看 bless 的用法.
bless 只能作用于引用.
这里将 $tv_horse 变为 Horse 的对象. (就是给 tv_horse 附加上 Horse 这个包名)
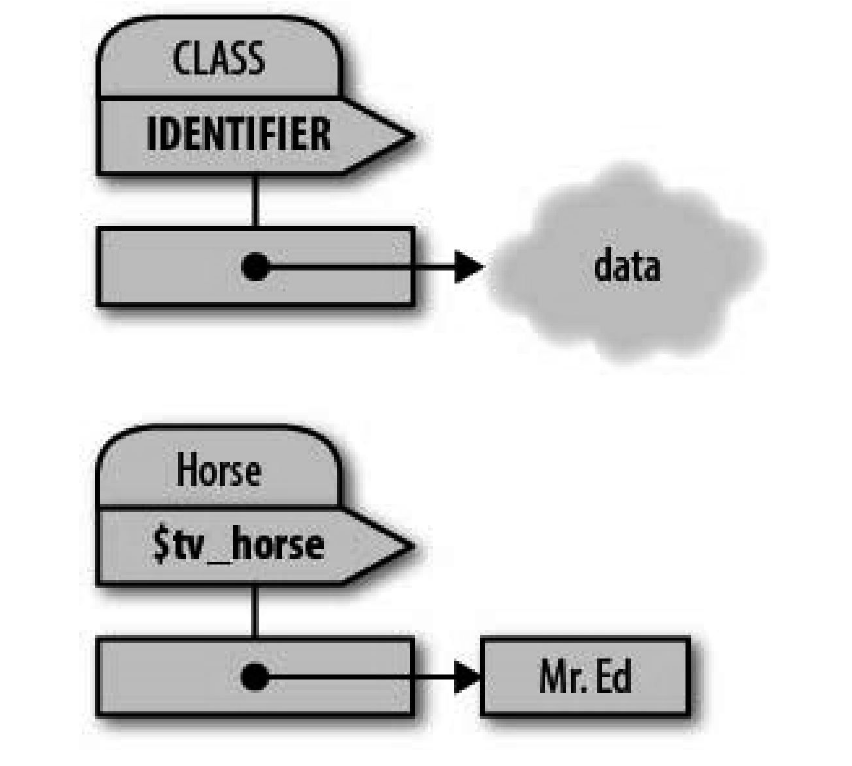
此时 tv_horse 是 Horse 类的一个实例,但是这个引用并没有什么改变,依旧可以用传统的解引用操作符.
15.2 调用实例方法
Perl 从被 bless 过的实例变量中取出类的名称,然后用它来定位和调用方法.
bless 的目的就是把一个类和这个引用关联起来,让 Perl 解释器能找到适当的方法.
1 | |
Perl 会直接查找 Horse::Sound, 做中生成的方法调用为:
1 | |
相当于 $tv_horse->sound 会传入一个默认参数.
15.3 访问实例数据
一个常见的方法,就是用过 shift 语句,将默认数组的第一个参数,传递给实例方法一个叫 $self 的标量.
1 | |
15.4 如何构建 Horse 的实例
让 Horse 类自动构建一个新的 Horse 实例:
1 | |
bless 会返回 \$name.
使用 named a方法构建一个实例,而不必直接生成引用:
1 | |
这里的第一个参数是默认参数 ‘Horse’.
named 就是一个构造函数.
大多数人使用一个叫做 new 的构造函数.
15.5 继承构造函数
1 | |
在一个实例上调用 speak 方法:
1 | |
得到的值为:
1 | |
15.6 编写能够使用类或实例作为参数的方法
需要判断方法是类还是实例上调用的.
类使用的方法默认参数是类名,而实例使用的方法默认参数是实例名.
最简单的方法是使用 ref 操作符. 如果 ref 作用于一个 bless 引用,就返回一个字符串 (类名). 如果作用于一个字符串,就返回 undef (像一个类名).
1 | |
15.7 为方法添加参数
为 Animal 类添加一个 eat 方法:
1 | |
类调用的方法一般用 $self, 实例调用的方法一般用 $either.
使用:
1 | |
第一个调用相当于:
1 | |
15.8 更有趣的实例
将散列的键作为成员变量,相应的值就是对应数据项的值.
如:
1 | |
15.9 一匹不同颜色的马
获取和设置颜色:
1 | |
15.10 收回存款
setter 的返回值考虑:
- 更新后的参数
- 之前的值
- 对象自身
- 成功/失败代码
避免当调用为空上下文时,存储前一项的值, 用 wantarray, 在 perldoc -f wantarray 中查看用法.
如果返回对象本身,可以使用这样的链式设定:
1 | |
因为每个 setter 的返回值是初始对象, 成为下一次方法调用的对象.
1 | |
15.11 不要查看 “盒子” 里面的内容
使用 setter 和 getter 而不窥视内部的数据结构.
15.12 更快的 setter 和 getter
15.13 getter 作为双倍的 setter
用一个方法来完成 getter 和 setter 的工作: 如果没有参数,就是一个取值操作 (用作 getter), 如果有参数,就是一个设值操作 (用作 setter).
1 | |
15.14 仅仅限制一个类方法或者实例方法
在 Perl 中,没有哪个方法定义的声明为: “这是一个类方法” 或者 “这是一个实例方法”, 因为它们都是 Perl 的子例程.
1 | |
可以用 Carp 模块来代替模块中的 die 和 warn 语句, croak 函数是另一种形式的 die 函数,carp 函数可用作 warn 函数的替代.
第16章 一些高级对象主题
16.1 通用方法
在定义类时,我们在每个包中通过全局变量@ISA创建了继承层次。在查找一个方法的过程中,Perl解释器会遍历@ISA树,直到找到一个匹配的方法或查找失败。
然而,在查找失败后,Perl解释器通常会在一个叫做 UNIVERSAL 的特殊类中查找,并调用其中的一个方法,如果成功匹配,则该方法就像位于任何其他类或超类中一样。
UNIVERSAL 是所有对象的基类,可以将任何方法放在这里, 如:
1 | |
其使得程序的所有对象都可以被 $some_object->fandando 调用.
UNIVERSAL 包中编写的可以算作通用方法.
应当尽力避免使用 UNIVERSAL 模块.
16.2 为了更好的行为而测试对象
除了为我们提供一个空间来放置通用方法以外,UNIVERSAL包同时预加载了两个非常有用的实用方法:DOES和can。
DOES 方法查询类和实例:
1 | |
can 查询特定的方法:
1 | |
都尽可能配合 eval 使用:
1 | |
16.3 最后的手段
在Perl解释器在继承树和UNIVERSAL中查找方法后,如果还不成功,查找将不会停止。Perl解释器将重复搜寻相同的层次(包括 UNIVERSAL),查找一个叫 AUTOLOAD 的方法。
定义一个叫 AUTOLOAD 的方法.
查看 Autoloader 和 SelfLoader 的核心模块文档.
16.4 使用 AUTOLOAD 创建访问器
16.5 更容易地创建 getter 和 setter
使用 Class::MethodMaker 模块.
16.6 多重继承
多重继承发生在当一个类的 @ISA 有不止一个元素的时候.
如:
1 | |
第17章 Exporter
17.1 use 语句在做什么
下面两个操作是等价的:
1 | |
冒号在类 UNIX 系统中被转换成目录分隔符,最终将以如下方式显示:
1 | |
我们不能使用前面使用的 .pl (即 Perl library 的缩写)作为扩展名,因为 use 语句找不到它。它只能使用 .pm 扩展名。
Perl解释器将查找当前@INC数组中的值,按顺序检查每个目录,查找一个叫Island的子目录中的Plotting子目录中包含名为Maps.pm的文件。
如果Perl解释器查找@INC数组后还找不到指定的文件,程序就由于查询不到所调用的库而终止(这可通过eval捕获)。否则,Perl读取并判断它读取的第一个文件。与require语句类似,最后一个表达式的值必须为真,否则程序将认为它遇到编译文件的错误而退出。
File::Basename模块文件的一部分可能如下所示:
1 | |
在BEGIN块中的第二步:Perl解释器在模块的包里自动调用一个叫做import的例程,传入整个导入列表。通常情况下,这个例程将对导入的命名空间中的一些名称指定别名(例如:File::Basename模块),然后映射到当前的命名空间之中(例如main)。
最后,整个过程被封装在一个BEGIN语句块内。这意味着use语句的操作在编译时间内生效,而不是运行时,
17.2 使用 Exporter 模块导入子例程
在 Exporter 模块中有一个标准的 import 方法,使用方式:
1 | |
或:
1 | |
17.3 @EXPORT 和 @EXPORT_OK
由 Exporter 模块提供的 import 子例程将检查模块包中的 @EXPORT 变量,判断哪个符号它默认导出。
如:
1 | |
@EXPORT 相当于提供了一个默认的导入列表.
以下两个调用是等效的:
1 | |
如果指定任何例程的名称,它们必须要么在@EXPORT列表中,要么在@EXPORT_OK列表中,
17.4 使用 %EXPORT_TAGS 分组
第18章 对象析构
调用一个清除对象的方法来销毁它.
18.1 清理
通过给对象一个 DESTROY 方法来请求销毁的通知.
当指向对象的最后一个引用消失时,以$bessie为例,Perl解释器自动调用该对象的DESTROY方法,就像我们主动调用这个方法一样。
1 | |
如添加一个 DESTROY 方法:
1 | |
这样在对象销毁时,可以获得相应的提示信息.
Perl解释器在程序执行完最后一个END语句块标志时立即执行最后的清理工作.
18.2 潜逃对象析构
一个对象包含另一个对象时,先销毁外部.
销毁一个引用, 如:
1 | |
而此时 DESTROY 方法则会被自动调用.
标准库的 File::Temp 模块提供临时文件. 该模块的 tempfile 例程知道如何生成临时文件,包括在哪儿放置.
使用 close 关闭文件句柄,使用 unlink 删除文件.
18.3 终结一个 “死去” 的Horse 类
18.4 间接对象表示法
如:
1 | |
可以写为,调用方法名在类名前,方法所需要的参数在类名后:
1 | |
18.5 子类中的额外实例
运用散列表容易增加额外的实例变量:
1 | |
18.6 使用类变量
若想要知道用 named 构造了那些动物,用一个散列来存储已经创建的动物:
1 | |
18.7 削弱参数
使用 Scalar::Util 模块下的 weaken 函数,将引用转化为弱引用.
当 Perl 解释器对某对象的活跃引用进行计数时,他不会对通过 weaken 函数转化的弱引用进行计数。如果所有普通引用都消失了,Perl解释器会把这个对象删除并且将所有弱引用变为undef。
第19章 Moose 简介
Moose 模块是 Perl 语言一个相对比较新的对象系统.
19.1 用 Moose 模块创建之前的 Animal 模块
Moose 中定义的 has,