概率论与数理统计课程笔记
第一章 概率论的基本概念
随机试验
对随机现象的观察,记录,实验统称为 随机试验.
特性:
- 在相同条件下重复进行
- 事先知道可能出现的结果
- 进行试验前并不知道哪个试验结果或发生
样本空间
定义:
随机试验 E 的所有结果构成的集合称为 E 的 样本空间, 记 $S = {e}$.
S 中的元素称 样本点. (也就是样本空间内的一点)
一个元素的单点集称为 基本事件 (也就是说,集合中只有一个样本点,这个集合就是基本事件)
事件 都是集合, 是集合的别称.
随机事件
S 的子集 A 为 E 的 随机事件 A, 简称 事件 A. (也就是说,样本空间的一个子集就是一个随机事件)
特征:
- 事件 A 是相应的样本空间 S 的一个子集,其关系可用 Venn 图来表示
- 事件 A 发生当且仅当 A 中的某一个样本点出现
- 事件 A 的表示可用集合,也可用语言来表示
事件的运算
和事件 $A \cup B$ ==> A 与 B 至少有一个发生
积事件 $A \cap B$, $A \cdot B$, $AB$ ==> A 与 B 同时发生.
互斥 $AB = \varnothing$ ==> A 与 B 不可能同时发生. (即一个样本点不可能既在 A 中又在 B 中)
逆事件 $\overline{A}$ ==> A 不发生
互逆
$$
\displaylines{
\begin{cases}
A \cup B = S \newline~ \newline
A B = \varnothing
\end{cases} }
$$
则 A 和 B 互逆. (和互补类似)
差事件 若表示事件 A 对事件 B 的差事件 $A \overline{B} = A - B$ ==> A 发生,B 不发生
集合运算:

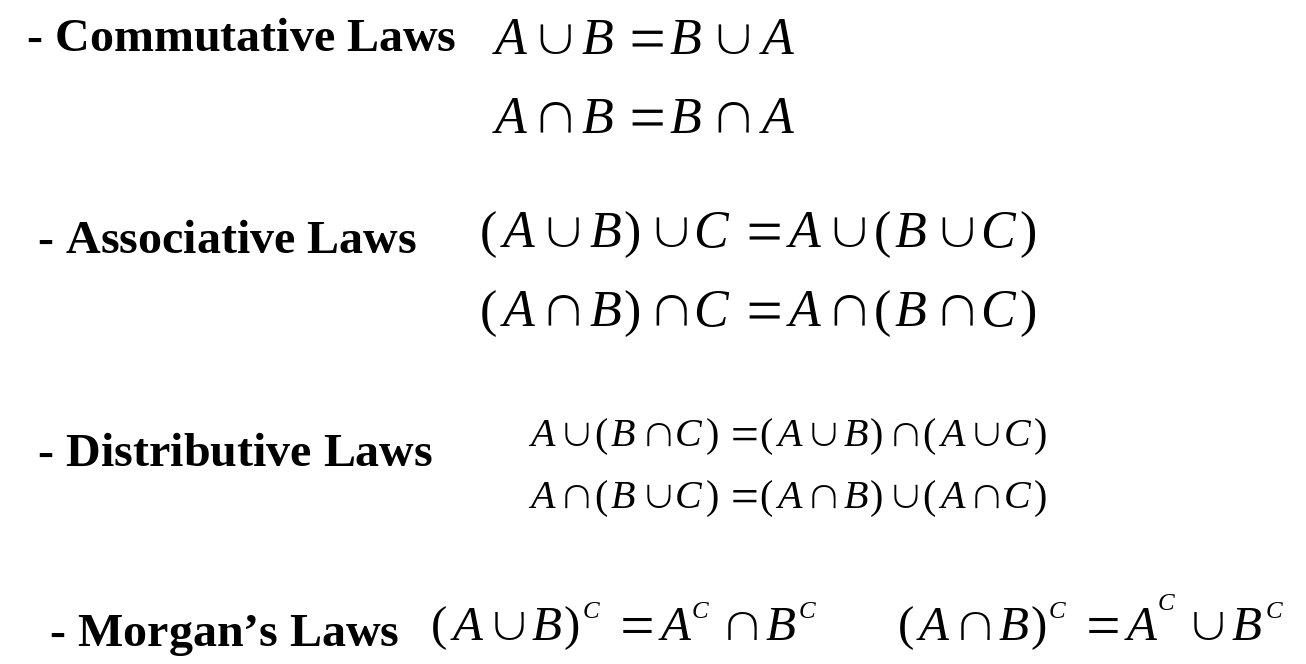
德摩根定理
$$
\displaylines{\overline{\bigcap_{i=1}^n A_i} = \bigcup_{i=1}^n \overline{A_i} \newline~ \newline
(可以看出, 逆, 对求和符号和 A_i 都起了作用, 文字表述其含义为 \newline~ \newline
所有事件的积的逆等于所有事件逆的和) \newline~ \newline
\overline{\bigcup_{i=1}^n A_i} = \bigcap_{i=1}^n \overline{A_i}}
$$
串联系统和并联系统
串联系统 一个损坏,系统就损坏:
$$
\displaylines{A = \bigcap_{i=1}^n A}
$$
$A_i$ 中有一个为空集, $A$ 就是空集.
并联系统 一个损坏,系统不损坏:
$$
\displaylines{A = \bigcup_{i=1}^n A_i}
$$
$A_i$ 中有一个为空集, $A$ 不为是空集.
频率与概率
频率
频率记为 $f_n(A)$:
$$
\displaylines{f_n(A) = \frac{n_A}{n}}
$$
$n$ 是总试验次数 (集合的总元素个数)
$n_A$ 是 $A$ 发生的次数 (集合 A 中的元素个数)
频率 $f_n(A)$ 反映了事件 A 发生的频繁程度.
频率的性质
- $0 \le f_n(A) \le 1$
- $f_n(S) = 1$
- 若 $A_1, A_2, …, A_k$ 两两互不相容, 则 $f_n(\bigcup_{i=1}^k A_i) = \sum_{i=1}^k f_n(A_i)$ (即,把$A_1, A_2, …, A_k$ 中所有元素放在一起的集合的频率,等于所有频率相加)
- $f_n(A)$ 随 $n$ 的增大渐趋稳定,记稳定值为 $p$ (如扔硬币,扔的次数越多,最后结果为正面的可能性才会接近 50%)
概率
定义
对样本空间 S 中任一事件 A, 定义一个实数 $P(A)$, 满足:
- 非负性: $P(A) \ge 0$
- 规范性: $P(S) = 1$
- 可列可加性: 若 $A_1, A_2, …, A_k, …$, 两两不相容,则 $P(\bigcup_{i=1}^\infty A_i) = \sum_{i=1}^\infty P(A_i)$ (即所有集合内的元素相加得到的集合的概率,等于所有集合概率的和)
称 $P(A)$ 为事件 A 的概率.
概率的性质
- $P(\varnothing) = 0$
- $A_1, A_2, …, A_n$, $A_iA_j = \varnothing$ (说明互斥) $\Rightarrow P(\bigcup_{i=1}^\infty A_i) = \sum_{i=1}^\infty P(A_i)$
- $P(A) = 1 - P(\overline{A})$
- $A \subset B \Rightarrow P(B - A) = P(B) - P(A) \Rightarrow P(B) \ge P(A)$
- 加法公式 : $P(A \cup B) = P(A) + P(B) - P(AB)$ (这其实就是通用公式, 对于互斥的来说, 就同之前说的 $P(A \cup B) = P(A) + P(B)$, 因为这里 $P(AB)=0$ )
一般情况下:
- $P(B - A) = P(B) - P(BA)$ (也就是从 B 的集合中,排除和 A 共有的部分, 就是 B 独有的部分)
- $P(C - B - A) = P(C) - P(CA \cup CB)$
可以看出来规律.
加法公式推导
$$
\displaylines{\because A \bigcup B = A \bigcup (B - A) \newline~ \newline
\Rightarrow P(A \cup B) = P(A \cup (B-A)) = P(A) + P(B-A) \newline~ \newline
= P(A) + P(B) - P(AB) }
$$
加法公式的推广 1
$$
\displaylines{P(A \cup B \cup C) = P(A) + P(B) + P(C) - P(AB) - P(AC) - P(BC) + P(ABC)}
$$
推导如下:
$$
\displaylines{P(A \cup B \cup C) \newline~ \newline
= P(A \cup B \cup (C - A - B)) \newline~ \newline
= P(A \cup B) + P(C) - P(AC \cup BC) \newline~ \newline
P(A) + P(B) - P(AB) + P(C) - P(AC) -P(BC) + P(ABC)}
$$
加法公式的推广 2
$$
\displaylines{P(\bigcup_{i=1}^n A_i) = \sum_{i = 1}^n P(A_i) - \sum_{1 \le i < j \le n} P(A_i A_j) + \sum_{1 \le i < j \le k \le n} P(A_i A_j A_k) - … + (-1)^{n-1}P(A_1A_2 … A_n)}
$$
奇数相加,偶数相减, 奇数指 $P(A) + P(B) …$ 或 $P(A_1A_2A_3) + P(A_4A_5A_6)$
古典概型 (等可能概型)
定义
试验 E 满足:
- S 中样本点有限 (有限性)
- 出现每一个样本点的概率相等 (等可能性) 如,1个袋子中5个白球和5个黑球,其中,每一个样本点就是指球,而不特是白球或黑球
这时, 古典概型概率计算公式 :
$$
\displaylines{P(A) = \frac{A 所包含的样本点数}{S 中的样本点数}}
$$
排列和组合公式
- 排列, 有顺序: $A_n^k = \frac{n!}{(n - k)!}$, 如 $A_5^2 = \frac{5!}{3!} = 5 \times 4$
- 组合,无顺序: $C_n^k = \frac{n!}{(n-k)!(k)!}$, 如 $C_5^2 = \frac{5!}{2!3!} = \frac{5 \times 4}{2 \times 1}$
实际推断原理
人们在撑起的实践中总结得到: “概率很小的事件在一次试验中实际上几乎是不可能发生的”
条件概率
英文 PPT
定义:
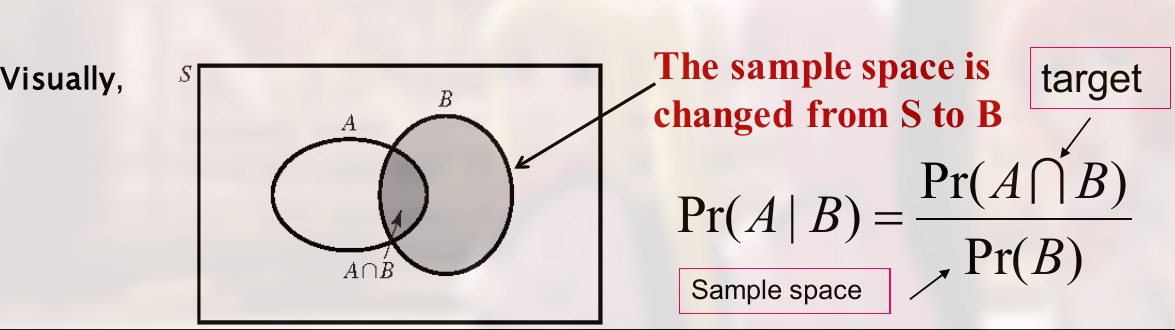
可以看到, 此时的 sample space 为 $Pr(B)$, 而 target 为 $Pr(A \cap B)$
一个例题:

注意是交集.
对一个概率添加条件:

$$
\displaylines
{
若有: \newline~ \newline
Pr(A_1 \cap A_2 \cap … \cap A_{n-1} | B) > 0 \newline~ \newline
则: \newline~ \newline
Pr(A_1 \cap A_2 \cap … \cap A_n | B) = \newline~ \newline
Pr(A_1|B) Pr(A_2|A_1 \cap B) Pr(A_3|A_1 \cap A_2 \cap B) … Pr(A_n|A_1 \cap A_2 \cap … \cap A_{n-1} \cap B)
}
$$
分割一个集合
如:

全概率公式为:
$$
\displaylines
{
Pr(A) = \sum_{i=1}^k Pr(A|B_i) Pr(B_i)
}
$$
条件版本的全概率公式:
$$
\displaylines
{
Pr(A|C) = \sum_{i=1}^k Pr(A|B_i \cap C) Pr(B_i|C)
}
$$
一个事件已经发生时,另一个事件发生的概率,
中文 PPT
定义:
$$
\displaylines{P(B|A) = \frac{P(BA)}{P(A)}\ \ \ P(A) \ne 0}
$$
( 记忆方法, 去掉 “|”, 写在上面,右侧的写在下面 )
表示 A 发生的条件下,B 发生的条件概率. (因为有一个已知的限定条件,所以叫做条件概率, 条件写在右边)
满足三条公理:
- 非负性: $P(B|A) \ge 0$
- 规范性: $P(S|A) = 1$
- 可列可加性: $A_1, A_2, …, A_k, …$, 两两互斥 $\Rightarrow P(\bigcup_{i=1}^\infty A_i | A) = \sum_{i=1}^\infty P(A_i | A)$
P(B|A) 具有概率的所有性质,如 加法公式
注意 $P(A|B)$ 和 $P(B|A)$ 并不相同.
条件概率的乘法公式
$$
\displaylines{P(AB) = P(A|B) \cdot P(B) = P(B|A) \cdot P(A) \newline~ \newline
P(ABC) = P(A|BC) \cdot P(BC) = P(A|BC) \cdot P(B|C) \cdot P(C)} \newline~ \newline
P(A_1A_2…A_n) = P(A_1)P(A_2|A_1)P(A_3|A_1A_2)…P(A_n|A_1…A_{n-1})
$$
也就是,所有交集形式的概率都可以转化为条件概率.
全概率公式与 Bayes
定义
$B_1, B_2, …, B_n$ 为 S 的一个划分,若:
- $B_1 \cup B_2 \cup … \cup B_n = S$
- $B_i B_j = \varnothing,\ i \ne j$ (表示每一个部分都互斥)
则这些概率相加则为一个事件的全部概率.
(一个事件和很多事件(这些事件互斥且构成总事件)相交, 求其概率就是将所有相交的部分相加)
全概率公式 为:
$$
\displaylines{P(A) = \sum_{j=1}^n P(A|B_j) \cdot P(B_j) }
$$
其中 $\sum_{j=1}^n P(A|B_j) \cdot P(B_j)$ 也就是 $\sum_{j=1}^n P(AB_j)$
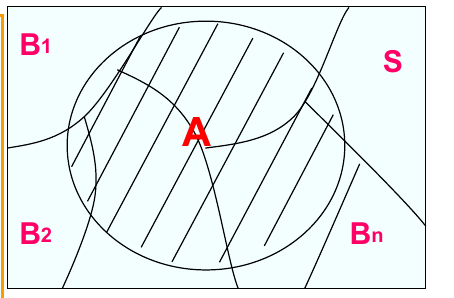
推导
$$
\displaylines{\because A = AS = AB_1 \cup AB_2 \cup … \cup AB_n \newline~ \newline
\therefore P(A) = \sum_{j=1}^n P(AB_j) \newline~ \newline
= \sum_{j=1}^n P(A|B_j) \cdot P(B_j)}
$$
应用全概率公式的关键
找到合适的划分.
Bayes 公式
借助全概率公式,用于计算条件概率:
$$
\displaylines{P(B_i|A) = \frac{P(B_i A)}{P(A)}}
$$
我们若要求 $Pr(A|B_i)$, 那么如果已知 $Pr(B_i|A)$ 则可利用 Bayes 公式求得.
将分子拆开, 对分母应用全概率公式:
$$
\displaylines{P(B_i|A) = \frac{P(A|B_i) P(B_i)}{\sum_{j=1}^n P(A|B_j) P(B_j)}}
$$
Conditional version of Bayes’theorem , 这里是 conditional on an event C:
$$
\displaylines
{
Pr(B_i|A) = \frac{Pr(B_i) Pr(A|B_i)}{\sum_{j=1}^k Pr(B_j) Pr(A|B_j)} \newline~ \newline
Pr(B_i|A \cap C) = \frac{Pr(B_i|C) Pr(A|B_i \cap C)}{\sum_{j=1}^k Pr(B_j|C) Pr(A|B_j \cap C)} \newline~ \newline
}
$$
PPT 中的
- 先验概率 (prior probability), 指在没有任何观测信息的情况下,某个事件发生的概率。它可以用来衡量某个事件发生的可能性,或者说某个条件下某个事件发生的可能性。
- 后验概率 (posterior probability), 指在给定一些观测信息之后,某个事件发生的概率。它可以用来衡量给定观测信息的情况下,某个事件发生的可能性。(常常就是指条件概率)
事件独立性与独立试验
定义
设 A, B 为两随机事件,如果 $P(AB) = P(A) P(B)$, 则称 A 与 B 相互独立
(即, B 的发生不会改变 A 的概率)
可以用 $P(A) = Pr(A|B)$ 来判断 A 和 B 是否独立.
如 $Pr(A|C) = Pr(A|C \cap B)$, 则可以判断为条件独立 (conditional independent)
若 $P(A) \ne 0, P(B) \ne 0$, 可以得到:
$$
\displaylines{P(AB) = P(A)P(B) = P(A|B)P(B) \newline~ \newline
P(A) = P(A|B) \newline~ \newline
or \newline~ \newline
P(AB) = P(A)P(B) = P(B|A)P(A) \newline~ \newline
P(B) = P(B|A)
}
$$
从这里也可以看出独立二字,当 $B$ 事件发生时, $A$ 事件的发生没有受到影响.
推论
$A, B$ 相互独立 $\Leftrightarrow \ \overline{A}, B$ 相互独立 $\Leftrightarrow \ A, \overline{B}$ 相互独立 $\Leftrightarrow \ \overline{A}, \overline{B}$ 相互独立
$$
\displaylines{\because P(AB) = P(A)P(B) \newline~ \newline
A \overline{B} = A - B \newline~ \newline
P(A \overline{B}) = P(A - B) = P(A) - P(AB) \newline~ \newline
= P(A) - P(A)P(B) \newline~ \newline
= P(A)[ 1-P(B) ] \newline~ \newline
= P(A)P(\overline{B})
}
$$
推广
设 $A_1, A_2, …, A_n$ 为 n 个随机事件,若对 $2 \le k \le n$, 均有:
$$
\displaylines{P(A_{i_1} A_{i_2} … A_{i_k}) = \prod_{j=1}^k P(A_{i_j})}
$$
(这里的如 $A_i$ 表示一个事件,另一个下标 1, 2, …, k 表示的是事件重复的次数, 这里的意思是每一次重复实验都独立)
则称 $A_1, A_2, …, A_n$ 相互独立。
独立试验 指任一次子试验的结果都不影响其他各子试验出现的结果.
重复试验 指各子试验是在相同条件下进行的.
条件独立 (conditional independence)
$$
\displaylines
{
Pr(A_{i_1} \cap … cap A_{i_j}|B) = Pr(A_{i_1}|B) … Pr(A_{i_j}|B)
}
$$
有:
$$
\displaylines
{
Pr(A_2) = Pr_(A_2|A_1) \newline~ \newline
Pr(A_2|B) = Pr_(A_2|A_1 \cap B)
}
$$
排列和组合
几个公式:
排列 :
$$
\displaylines
{
P_n^m = \frac{n!}{(n-m)!}
}
$$
组合:
$$
\displaylines
{
C_n^m = \frac{P_n^m}{m!} = \frac{n!}{(n-m)! m!} \newline~ \newline
C_n^m = C_n^{n-m} \newline~ \newline
C_n^0 = C_n^n = 1
}
$$
1.7 排列
1.7.1 乘法定律
有 k 个 parts, 每个 part 的概率为 $n_i$, 则总概率为:
$$
\displaylines
{
N(S) = n_1 n_2 … n_k
}
$$
1.7.2 排列
无放回抽样 (sampling without replacement), 应该也叫做不重复排列, 定义: 如, 第一次从 n 个卡片重抽出 1 张, 第二次从剩下 $n-1$ 个卡片中抽出 1 张…
三次无放回抽样的总数为:
$$
\displaylines
{
n (n-1) (n-2)
}
$$
符号 $P_{n,k}$ 的含义, 抽样 n 个元素, 每次取 k 个. 则可能的情况共有:
$$
\displaylines
{
P_{n,k} = n (n-1) … (n-k+1) = \frac{n!}{(n-k)!}
}
$$
(这似乎就是排列组合中的排列)
全排列 $P_n^n = n(n-1)… \times 3 \times 2 \times 1 = n!$
注意: $0! = 1$
放回抽样 (sampling with replacement), 也可以称为重复排列, 如取一个盒子中的小球, 取出一个后将其放回再取第二次.
抽样 k 个物体, 则可能的情况共有:
$$
\displaylines
{
S = \{(x_1, …, x_k) : X_i \in \{1,…,n\} \} \newline~ \newline
N(S) = n^k
}
$$
放回抽样和不放回抽样的差别 : 放回抽样没有顺序, 而不放回抽样有.
生日问题 :
解法:
由于是至少两人, 所有情况很多, 可以有 3 人, 4 人 … 因此从另一个角度分析, 计算抽出来的每个人生日都不同的情况.
抽出 k 个人, 其生日总的可能情况为:
$$
\displaylines
{
Pr = 365^k
}
$$
(每个人都有可能是 365 天中的一天)
抽出来的人生日都不在同一天的情况:
$$
\displaylines
{
Pr = p_{365, k}
}
$$
(相当于是从 365 天中不重复抽样了 k 天)
因此:
$$
\displaylines
{
Pr(A) = 1 - Pr(A^c) \newline~ \newline
= 1 - \frac{p_{365,k}}{365^k}
}
$$
1.8 组合
排列和组合的关系:
$$
\displaylines
{
排列 = 组合 \times k!
}
$$
(组合表示只关心数目k, 不关心抽出的 k 的内部次序, 而 $k!$ 表示 k 个内部排序)
因此:
$$
\displaylines
{
C_{n,k} = \binom{n}{k} = \frac{P_{n,k}}{k!} = \frac{n!}{k!(n-k)!}
}
$$
(可以借此在排列和组合问题中切换)
符号的记法, 写在前面的放上面.
技巧 , 有位置就有顺序. 如

这里有八个职位, 也就相当于八个位置, 每个人坐的位置都会导致结果不同, 因此也就有了顺序.
挑选礼物问题 (无顺序的放回抽样 unordered sampling with replacement)
有 7 种类型的商品, 挑选 12 个礼物, 顺序不重要, 相同的类型至少挑选一次. 这里则为:
$$
\displaylines
{
C_{7+12-1,12} = 18564
}
$$
无序有放回公式为:
$$
\displaylines
{
C_{n+k-1, k}
}
$$
这个可以理解为, 有 n 个相同球(指无序样本), 放入 k 个不同的盒子, 每个盒子中能装的球的个数不限(指有放回抽样). (上面那道题可以看作, 12 个球, 7 个盒子)
(有序和无序说明的是样本的性质, 有放回和无放回说明的是抽样方式)
推导
用 隔板法 .
如 $n=2$, 有 p 个小球, 我们在小球之间插一个隔板, 隔板左边的放入第一个盒子, 隔板右边的放入第二个盒子
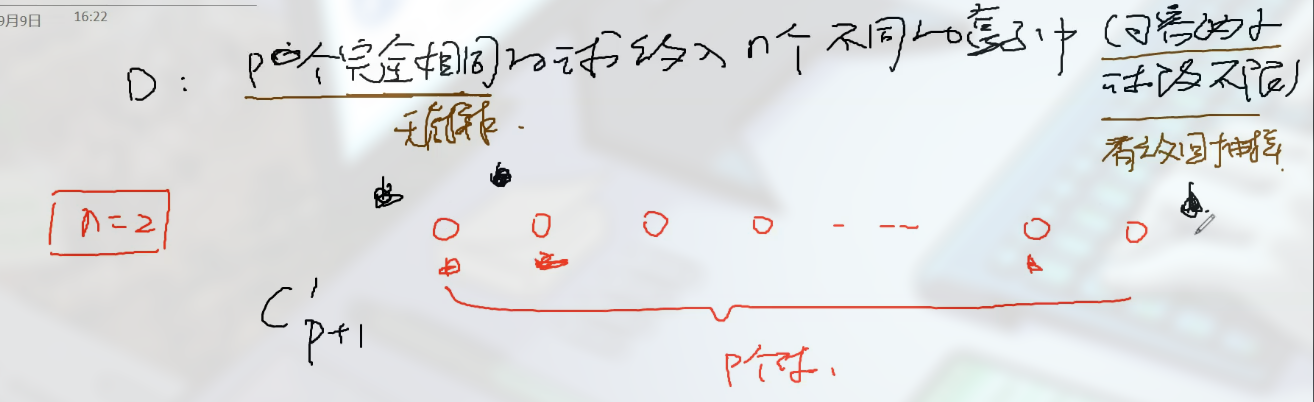
由于有 $p$ 个球, 因此有 $p+1$ 个隔板的位置.
当 $n=2$ 时, 只需要 1 个隔板, 毕竟一个就可以把样本分为 2 份.
当 $n=3$ 时, 需要 2 个隔板. 等
此时问题已经转化为了 插入隔板位置 的问题.
每插入一个隔板都会对后续隔板产生影响 (多了一个可插入的位置). 但隔板的插入是没有顺序的, 因此还会除以顺序数.
$$
\displaylines
{
n = 1 \rightarrow \frac{C_{p+1}^1}{1!} \newline~ \newline
n = 2 \rightarrow \frac{C_{p+1}^1 C_{p+2}^1}{2!} \newline~ \newline
n = n-1 \rightarrow \frac{C_{p+1}^1 C_{p+2}^1 … C_{p+n-1}^1}{(n-1)!} \newline~ \newline
= \frac{(p+n-1) … (p+1)}{(n-1)!} = C_{n+p-1}^{n-1} = C_{n+p-1}^p
}
$$
(为什么最后是 $n-1$ 个板子, 因为只需要 $n-1$ 个板子就能将元素分为 $n$ 份)
玩扑克牌:

解法为:
$$
\displaylines
{
p = \frac{13^4}{C_{52,4}}
}
$$
1.8.2 二项式系数
组合:
$$
\displaylines
{
C_{n,k} = \binom{n}{k} = \frac{P_{n,k}}{k!} = \frac{n!}{k!(n-k)!}
}
$$
这个数也被称为 二项式系数 (biomial coefficient)
二项式定理为:
$$
\displaylines
{
(x+y)^n = \sum^n_{k=0} \binom{n}{k} x^k y^{n-k}
}
$$
1.9 多项式系数
多项式系数 (multinomial coefficient) 如:
$$
\displaylines
{
\binom{20}a{8,8,4} = \frac{20!}{8!8!4!}
}
$$
定义: n 个不同的元素可以分为 k 个不同的组. 第 j 个组包含的元素数量为 $n_j$, 且 $n_1 + n_2 + … + n_k = n$
有:
$$
\displaylines
{
\binom{n}{n_1} \binom{n-n_1}{n_2} \binom{n-n_1-n_2}{n_3}…\binom{n-n_1-…-n_{k-2}}{n_{k-1}} = \frac{n!}{n_1! n_2! … n_k!}
}
$$
(这个式子的含义为, 从 n 个位置中找 $n_1$ 个给第一组, 从剩下 $n-n_1$ 个位置中找 $n_2$ 个给第二组 …)
相当于是将 n 个元素(无序)放入 k 个不同的盒子, 每个盒子能装的个数固定(不放回).
这个数就被称为 多项式系数 (multinomial coefficient).
易错例题:

计算:
- all possible outcomes
- target events
的方法.

这道题, 要求求的为 $Pr(A_1 \cup A_2 \cup A_3)$
第二章 随机变量及其分布
随机变量
定义
设随机试验的样本空间为 $S = {e}$, 若 $X = X(e)$ 为定义在样本空间 $S$ 上的实值单值函数,则称 $X = X(e)$ 为随机变量. ($X$ 虽然叫随机变量, 但其是一个函数)
$X = X(e)$ 可以理解为,$X$ 的值等于 $e$ 的函数.
特点
- 一般采用大写英文字母 $X, Y, Z$ 来表示随机变量
- 引入随机变量的目的是用来描述随机现象
常见的两类随机变量:
- 离散型的
- 连续型的
离散型随机变量及其分布
定义
取值至多可数的随机变量为 离散型的随机变量.
以下表明离散和非离散的示意: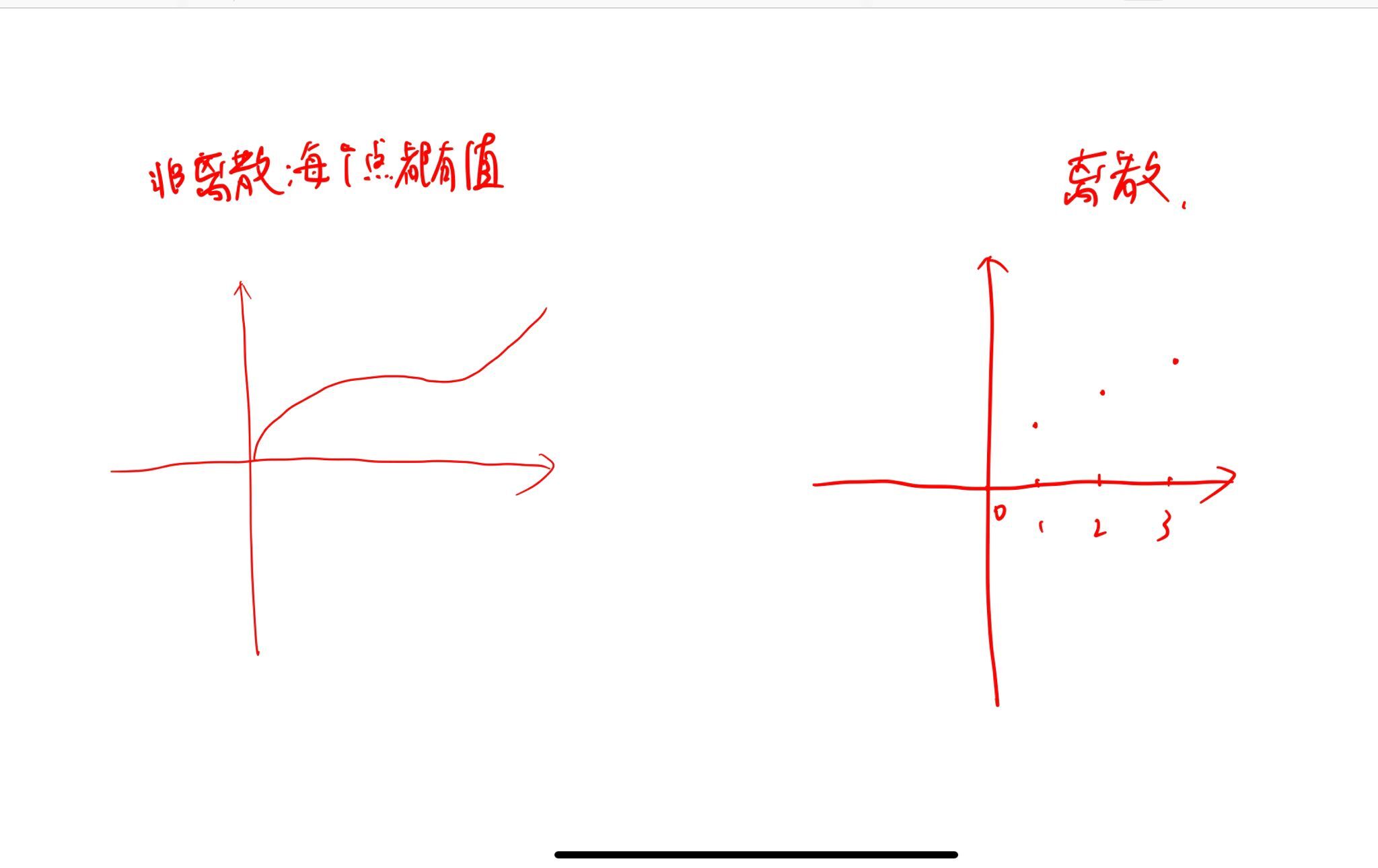
概率分布律 为:
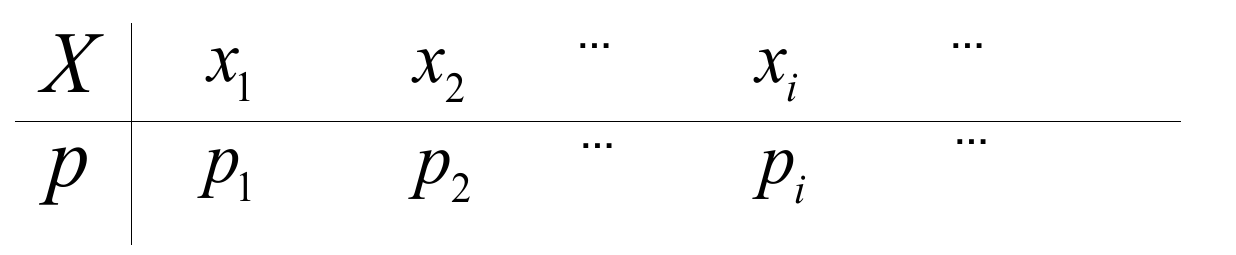
( $p_i \ge 0, \sum_{i=1}^\infty p_i = 1$)
也就是用来描述随机变量和其概率.
某随机变量的分布是, 该随机变量能取道某些值的一系列概率的集合.
$$
\displaylines{
概率分布律
\begin{cases}
写出所有可能取值 \newline~ \newline
写出每个取值相应的概率
\end{cases} }
$$
几个重要的离散型随机变量分布
这些分布都是根据 概率密度函数的特点 命名的.
如下面的 0-1 分布, 就是概率密度函数的参数只取 0 和 1.
概率函数和概率密度函数的关系:

即, 一个是离散的, 一个是连续的.
伯努利模型
独立试验序列: $E_1, E_2 … E_n$ 独立
n 重独立实验: $E, E, …, E$ 独立, $E^n$
伯努利实验: 指结果只有两种的实验 (如, 正反, 中与不种, 次与合格)
n 重伯努利试验, 指做 n 次伯努利试验(同一个试验做 n 次), 试验间独立, 结果只有两种.
定理, $A$ 的概率为 $p\ (0 < p < 1)$, 那么 $\overline{A}$ 的概率为 $1-p$
n 重伯努利试验中 A 发生 k 次:
$$
\displaylines
{
P_{n,k} = C_n^k p^k (1-p)^{n-k} = C_n^k p^k q^{n-k}, \ \ q=1-p
}
$$
什么是二项式
$$
\displaylines
{
(a+b)^n = (a+b) (a+b) (a+b) … (a+b) \newline~ \newline
考虑什么时候会出现\ a^n: \newline~ \newline
只有每一个项拿出一个\ a 才行, 因此为 \newline~ \newline
= C_n^n a^n + … \newline~ \newline
此时考虑第二项,\ 形成\ a^{n-1}, 需要 n-1 个项拿出\ a\ 剩下一项拿出\ b\ : \newline~ \newline
= C_n^n a^n + C_n^{n-1} a^{n-1}b + … \newline~ \newline
以此类推: \newline~ \newline
= C_n^n a^n + C_n^{n-1} a^{n-1}b + C_n^{n-2} a^{n-2}b^2 + …
}
$$
因此如果我们想得到 $n^k$, 则可以写出:
$$
\displaylines
{
P_{n,k} = C_n^k p^k (1-p)^{n-k}
}
$$
0-1 分布
其也被称为 伯努利 分布 (Bernoulli Trials/Process)
$X$ 的分布律为:
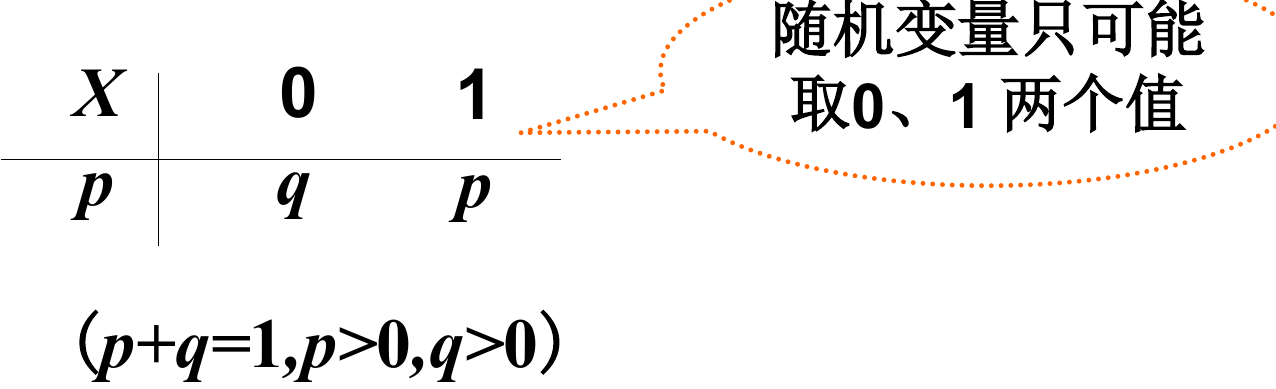
称为 $X$ 服从参数为 p 的 0-1 分布 或亮点分布.
记为 $X \sim 0-1(p)$ 或 $B(1,p)$
(记忆方法, $p$ 总是在最后一位, 这里的 $B$ 可能为 Binomial)
还可写为:
$$
\displaylines{P(X=k) = p^k(1-p)^{1-k},\ \ k = 0,1}
$$
只有两个可能结果的试验,称为 贝努利试验
伯努利分布和伯努利试验的区别:
二项分布
n 重贝努利试验: 设试验 E 只有两个可能的结果 $A 与 \overline{A}\ \ , P(A) = p, 0 < p < 1$, 将 E 独立地重复进行 n 次,则称这一串重复的独立试验为 n 重贝努利试验.
(独立,保证每次试验结果不互相影响. 重复,保证在相同的条件下重复进行)
设 A 在 n 重贝努利试验中发生 X 次,则 $P(X=k) = C_n^k p^k (1-p)^{n-k},\ \ \ k = 0,1,…$ 并称 X 服从参数 $n,p$ 的二项分布.
(这里的 $C_n^k$ 表示从 n 次试验中选 k 次发生)
记为:
$$
\displaylines{X \sim B(n, p)}
$$
注:
$$
\displaylines{1 = (p + q)^n = \sum_{k=0}^n C_n^k p^k q^{n-k},\ \ \ 其中\ \ q = 1-p}
$$
泊松分布 (Poisson 分布)
泊松分布使一些二项分布更易计算.
若随机变量 X 的概率分布律为:
$$
\displaylines{P(X=k) = f(x|\lambda) = \frac{\lambda^k e^{- \lambda}}{k!},\ \ \ k=0,1,2,…,\ \ \lambda > 0}
$$
则称 X 服从参数为 $\lambda$ 的泊松分布.
记为:
$$
\displaylines{X \sim P(\lambda)}
$$
(P 是 Poisson 的简写)
泊松定理
二项分布与泊松分布有下面的近似结果:
当 $n > 10, p < 0.1$ 时,
$$
\displaylines{C_n^k p^k (1-p)^{n-k} \approx \frac{e^{-\lambda} \lambda^k}{k!}, \ \ \lambda = np}
$$
推导
$$
\displaylines{\because \lambda = np \newline~ \newline
C_n^k(1-p)^{n-k} = \frac{n!}{k!(n-k)!}p^k(1-p)^{n-k} \newline~ \newline
= \frac{n!}{k!(n-k)!}( \frac{\lambda}{n})^k ( 1 - \frac{\lambda}{n} )^{n-k} \newline~ \newline
= \frac{\lambda^k}{k!} \frac{n (n-1)…(n-k+1)}{n^k} \frac{[ (1 - \frac{\lambda}{n})^{ -\frac{n}{\lambda} } ]^{- \lambda}}{ (1 - \frac{\lambda}{n} )^k } \newline~ \newline
当 n 充分大和适当的 \lambda 时 \newline~ \newline
\frac{n (n-1)…(n-k+1)}{n^k} \approx 1, ( 1- \frac{\lambda}{n} )^k \approx 1, [ (1 - \frac{\lambda}{n})^{ -\frac{n}{\lambda} } ] \approx e^{-\lambda} \newline~ \newline
因此 \newline~ \newline
C_n^k(1-p)^{n-k} \approx \frac{e^{-\lambda} \lambda^k}{k!}}
$$
超几何分布
若随机变量 X 的概率分布律为:
$$
\displaylines{P(X = k) = \frac{C_a^k C_b^{n-k}}{C_N^n}, \ \ \ k = l_1, l_1 + 1, …, l_2 \newline~ \newline
其中,\ l_1 = max(0,n-b), \ l_2 = min(a,n)}
$$
称 X 服从 超几何分布
其为什么叫超几何分布可以查看其他博客.
几何分布
若随机变量 X 的概率分布律为:
$$
\displaylines{P(X = k) = p(1-p)^{k-1}, \ \ k=1,2,3,…, \ \ 0 < p < 1}
$$
称 X 服从参数 p 的几何分布.
巴斯卡分布
若随机变量 X 的概率分布律为:
$$
\displaylines{P(X=k) = C_{k-1}^{r-1} p^r (1-p)^{k-r}, \ \ k=r, r+1, r+2, …, \newline~ \newline
其中r 为整数, \ 0 < p < 1}
$$
随机变量的分布函数
定义
随机变量 $X$, 若对任意实数 $x$, 函数
$$
\displaylines{F(x) = P(X \le x)}
$$
称 $X$ 的分布函数. 概率函数的值是累加的结果,因此也叫 累加概率函数 (cumulative distribution function), 即 c.d.f. .
比如: $X$ 是离散的,可以取得值为 $1,2,3,4$, 其对应的概率分别为 $0.1, 0.2, 0.3, 0.4$那么:
$$
\displaylines{F(1) = P(X \le 1) = P(1) = 0.1 \newline~ \newline
F(2) = P(X \le 2) = P(1) + P(2) = 0.1 + 0.2 = 0.3 \newline~ \newline
F(3) = P(X \le 3) = P(1) + P(2) + P(3)= 0.1 + 0.2 + 0.3 = 0.6 \newline~ \newline
F(4) = P(X \le 4) = P(1) + P(2) + P(3) + P(4)= 0.1 + 0.2 + 0.3 + 0.4 = 1 }
$$
其分布函数可以写为:
$$
\displaylines{F(x) = P(X \le x) =
\begin{cases}
0, \ \ x < 1 \newline~ \newline
0.1, \ \ x < 2 \newline~ \newline
0.3, \ \ 2 \ge x < 3 \newline~ \newline
0.6, \ \ 3 \ge x < 4 \newline~ \newline
1, \ \ 4 \ge x
\end{cases}}
$$
图像为: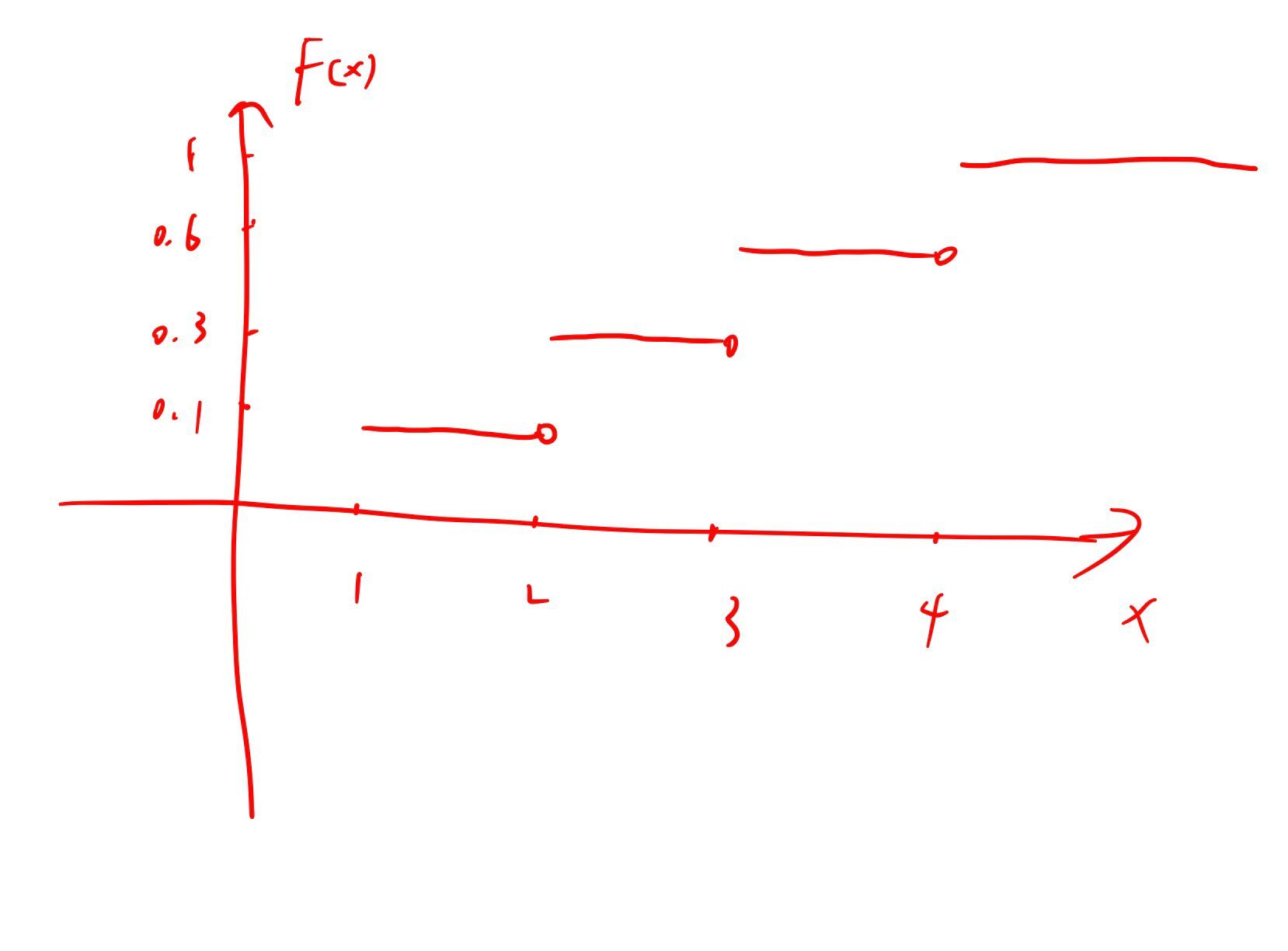
性质
- $0 \le F(x) \le 1$
- $F(x)$ 单调不减, 且 $F(-\infty) = 0, \ \ F(+\infty) = 1$
- $F(x)$ 有连续,即 $F(x+0) = F(x)$
同时也有:
- $Pr(X > x) = 1 - F(x)$
- Pr(x_1 < X \le x_2) = F(x_2) - F(x_1)
- Pr(X = x) = F(x) - F(x^-)
分位数函数 (quantile function) 的定义: $p \in (0,1)$, 定义 $x$ 为 $x = F^{-1}(p)$, 满足 $F(x) \ge p$ 的最小 x 的值. 此时 $F^{-1}(p)$ 被称为 X 的 p 分位 (the p quantile of X) , 而函数 $F^{-1}$ 也被称为 分位函数 (quantile function)
(为什么称为分位函数, 因为其值为 $0 \sim 1$ 也就相当于是分数)
$$
\displaylines
{
F^{-1}(p)
}
$$
的含义实际上就是积分, 直到值为 p.
示例:

连续型随机变量及其概率密度函数
定义
对于随机变量 $X$ 的分布函数 $F(x)$, 若存在非负的函数 $f(x)$, 使对于任意实数 $x$, 有:
$$
\displaylines{F(x) = \int_{-\infty}^x f(t) dt}
$$
(积分式,求面积, $f(t)$ 为曲线所在的函数)
则称 $X$ 为 连续型随机变量 , 其中 $f(x)$ 称为 X 的 概率密度函数 (probability mass function, p.m.f), 简称密度函数,
$f(x)$ 的性质
- $f(x) \ge 0$
- $\int_{-\infty}^{+\infty} f(x) dx = 1$
- 对于任意实数 $x_1, x_2 \ (x_2 > x_1)$
$$
\displaylines{P{x_1 < X \le x_2} = F(x_1) - F(x_2) = \int_{x_1}^{x_2} f(t) dt}
$$
- 在 $f(x)$ 连续点 $x$, $F^\prime (x) = f(x)$
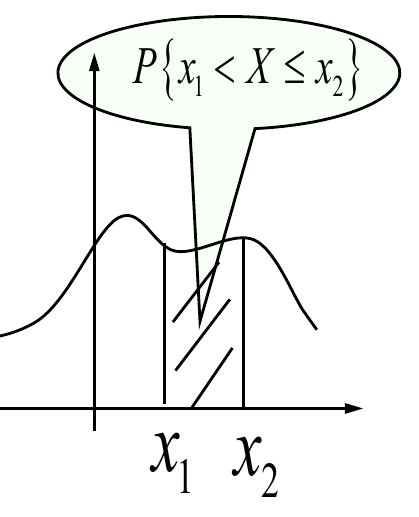
几个重要的连续型随机变量分布
这些分布都是根据 概率密度函数的特点 命名的.
均匀分布
定义
设随机变量 $X$ 具有概率密度函数:
$$
\displaylines{f(x) =
\begin{cases}
\frac{1}{b-a}, \ \ x \in (a,b) \newline~ \newline
0, \ \ 其他
\end{cases}}
$$
称 $X$ 在区间 (a,b) 上服从 均匀分布.
记为 $X \sim U(a,b)$. (U 可能是指 Uniform)
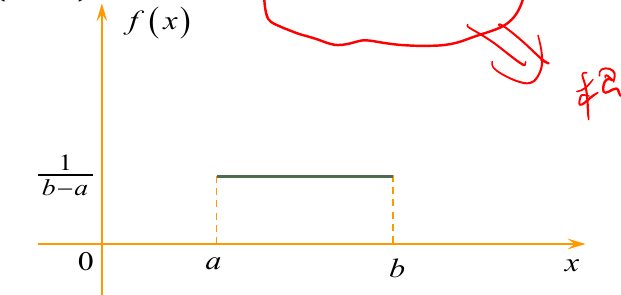
可看出,在 $x \in (a,b)$ 其积分出来的值均匀变化.
为什么最大值为 $\frac{1}{b - a}$ 也可以看出来,矩形的面积为 $1$, 底边为 $b - a$, 那么高就为 $\frac{1}{b - a}$
正态分布
定义
设 $X$ 的概率密度函数为:
$$
\displaylines{f(x) = \frac{1}{\sqrt{2 \pi} \sigma} e^{- \frac{(x - \mu)^2}{2 \sigma^2}}, \ \ - \infty < x < + \infty, \newline~ \newline
其中 -\infty < \mu < \infty, \ \ \sigma > 0 为常数}
$$
称 $X$ 服从参数 $\mu, \ \sigma$ 的正态分布 (Gauss 分布), 记为 $X \sim N(\mu, \sigma^2)$
正态分布名称的由来
正态分布 (normal distribution). 由于这种数据分布太过于常见,基本能描述所有常见的事务和现象,因此为 normal 的 distribution.
性质
- $f(x)$ 关于 $x = \mu$ 对称
- $f_{max} = f(\mu) = \frac{1}{\sqrt{2 \pi} \sigma}$
- $\underset{\left\vert x - \mu \right\vert \to \infty}{\lim} f(x) = 0$
图像
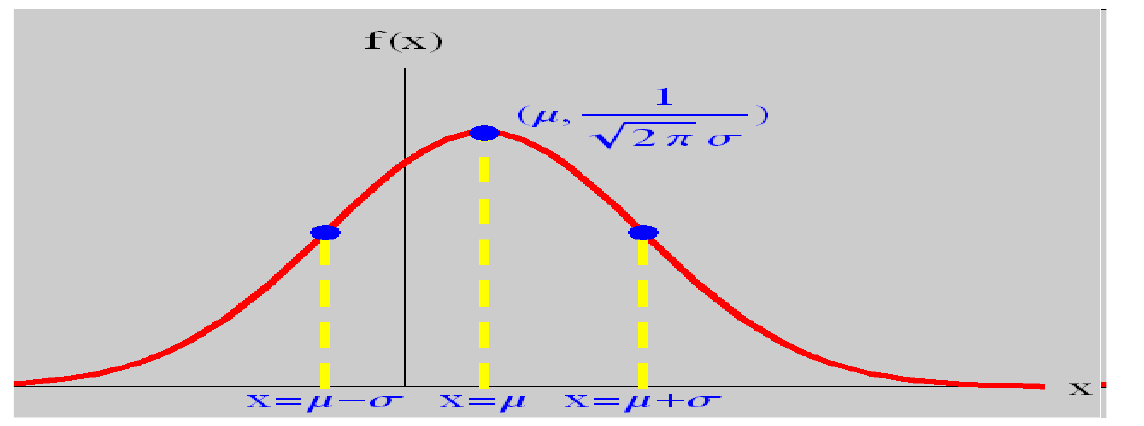
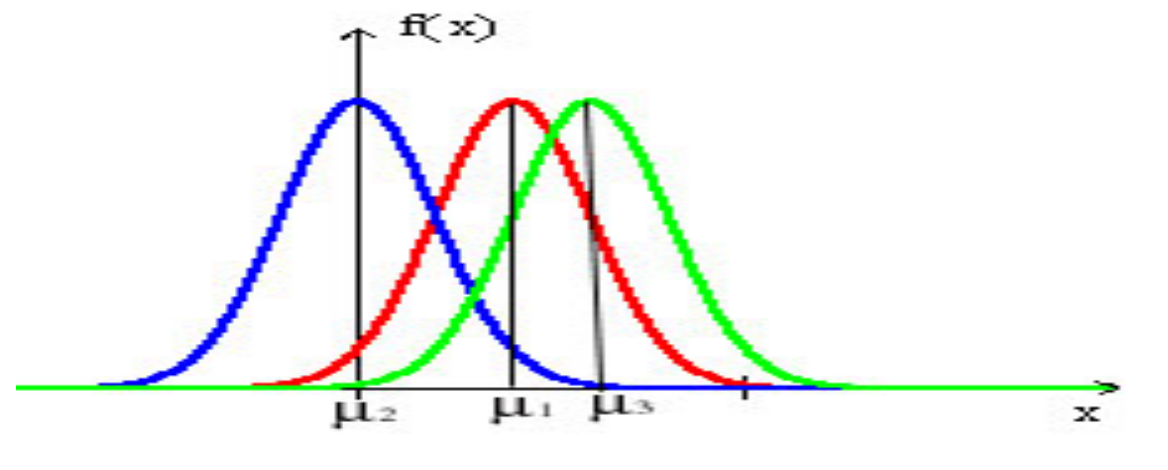
当 $\sigma$ 固定时, $\mu$ 让密度函数沿 x 轴做平移变换 (即,决定对称轴的位置):
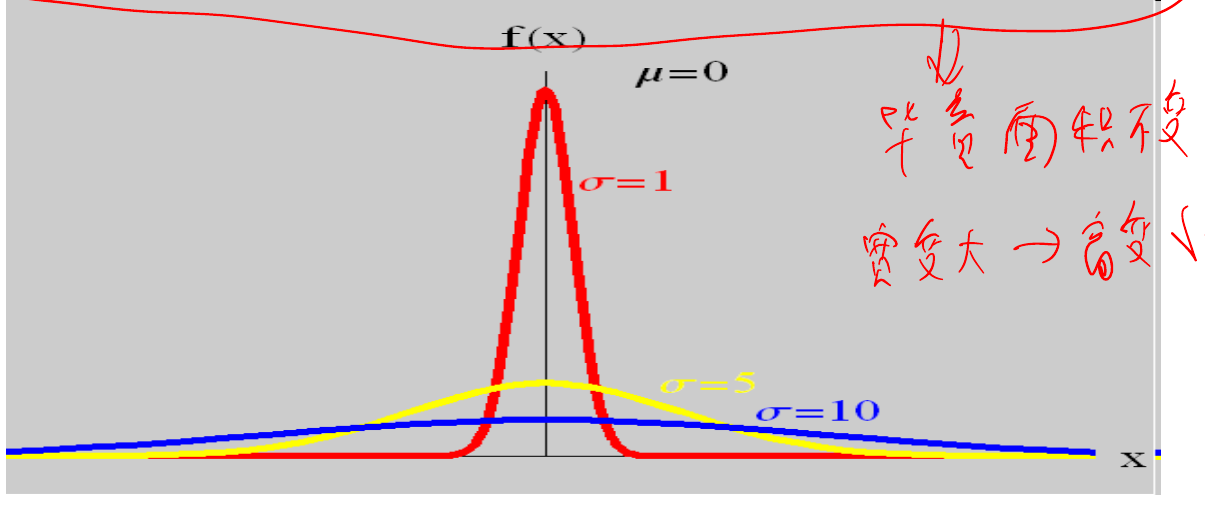
当 $\mu$ 固定时,$\sigma$ 影响图像的宽度,但图像的总面积不变, 因此:
若 $Z \sim N(0,1)$, 称 $Z$ 服从 标准正态分布:
$Z$ 的密度函数为:
$$
\displaylines{ \phi (x) = \frac{1}{\sqrt{2 \pi}} e ^{- \frac{x^2}{2}} }
$$
$Z$ 的分布函数为:
$$
\displaylines{ \phi (x) = \int_{-\infty}^x \frac{1}{\sqrt{2 \pi}} e ^{- \frac{t^2}{2}} dt}
$$
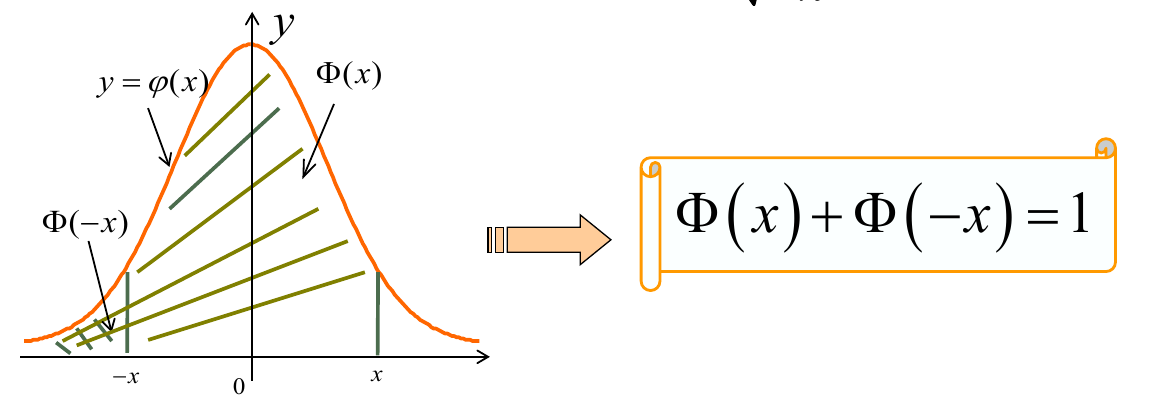
对于标准正态分布来说, 有:
$$
\displaylines
{
\Phi (-x) = 1 - \Phi (x)
}
$$
(即, x 轴负半轴的总概率等于 1 减去正半轴的总概率, 毕竟对称)
推导为:
$$
\displaylines
{
Pr(X \le x) = Pr(X \ge -x) \newline~ \newline
Pr(X \le x) = \Phi (x)\ and\ Pr(X \ge -x) = 1 - \Phi (-x) \newline~ \newline
\Phi (-x) = 1 - \Phi (x)
}
$$
正态分布转换为标准正态分布计算
$$
\displaylines{P(X \le b) = \int_{-\infty}^b \frac{1}{\sqrt{2 \pi} \sigma} e^{- \frac{(x - \mu)^2}{2 \sigma^2}} dx \newline~ \newline
\frac{x - \mu}{\sigma} = t \newline~ \newline
P(X \le b) = \int_{-\infty}^{ \frac{b- \mu}{\sigma}} \frac{1}{\sqrt{2 \pi}} e^{- \frac{(t)^2}{2}} dt \newline~ \newline
P(X \le b) = \phi ( \frac{b - \mu}{\sigma})}
$$
指数分布
这里的指数指 自然指数
定义
设 $X$ 的密度函数为
$$
\displaylines{f(x) =
\begin{cases}
\lambda e^{- \lambda x}, \ \ x > 0 \newline~ \newline
0, \ \ x \le 0
\end{cases} \newline~ \newline
其中 \lambda > 0 为常数}
$$
则称 $X$ 服从参数为 $\lambda$ 的 指数分布
记为 $X \sim E( \lambda )\ 或\ X \sim Exp( \lambda )$ (这里的 E 指 Exponent)
$X$ 的分布函数为:
$$
\displaylines{F(x) = \int f(x) =
\begin{cases}
\int \lambda e^{- \lambda x} dx = 1 - e^{- \lambda x}, \ \ x > 0 \newline~ \newline
\int 0 dx = 0, \ \ x \le 0
\end{cases}}
$$
性质
- 无记忆性
即,如果X表示等待时间,那么无记忆性说明只要还没等到,那么剩余等待时间仍然服从参数为λ的指数分布.
数学语言描述如下:
$$
\displaylines{ t_0 > 0,\ t > 0 \newline~ \newline
P(X > t_0 + t| X > t_0) = \frac{P(X > t_0 + t)}{P(X > t_0)} \newline~ \newline
= \frac{1 - F(t_0 + t)}{1 - F(t_0)} \newline~ \newline
= P(X > t) }
$$
$t$ 为还需等待的时间,和之前已经等待了多久无关.
随机变量函数的分布
见 PPT.
第三章 多元随机变量及其分布
二元离散型随机变量
定义
设 E 是一个随机试验,样本空间 $S = {e}$, 设 $X = X(e)\ 和\ Y = Y(e)$ 是定义在 S 上的随机变量, 由它们构成的向量 $(X,Y)$ 叫做 二元随机变量 或 二维随机变量.
联合概率分布
定义
若二元随机变量 $(X,Y)$ 可能取到的 不同值 是有对或可列无对, 则称 $(X,Y)$ 是离散型随机变量.
离散型随机变量的联合概率分布律:

对于离散型随机变量 $(X,Y)$, 联合分布律为:
$$
\displaylines{P(X=x_{i}, Y=y_{j}) = p_{ij}, \ \ i,j = 1,2…}
$$
(对于每一个概率而言, $X,Y$ 的值都给定)
性质
- $p_{ij} \ge 0, \ \ i,j = 1,2…$ (即每一个概率都大于 0)
- $\sum_{i=1}^\infty \sum_{j=1}^\infty p_{ij} = 1$ (即全部相加为 1)
边际分布 Marginal Distributions
边际指的是 $(X,Y)$ 中有一个值确定时计算概率分布.
对于离散型随机变量 $(X,Y)$, 边际分布律为:
$$
\displaylines{P(Y=y_j) = P(X< +\infty, Y=y_j) = \sum_{i=1}^\infty p_{ij} = p_{\bullet j} \ \ , j = 1,2… \newline~ \newline
P(X=x_i) = P(X=x_i, Y< +\infty) = \sum_{i=1}^\infty p_{ij} = p_{j\bullet} \ \ , i = 1,2…}
$$
也就是说,如 $p_{\bullet j}$, 如 $j=1$ 就是求 $p_{11} + p_{21} + p_{31}…$, 接着继续求 $j = 2,3,…$ 的情况并相加.
条件分布
定义
设 $(X,Y)$ 是二元离散型随机变量,对于固定的 $y_j$, 若 $P(Y=y_i) > 0$, 称:
$$
\displaylines{P(X=x_i|Y=y_j) = \frac{P(X=x_i, Y=y_j)}{P(Y=y_j)} = \frac{p_{ij}}{p_{\bullet j}}, \ \ i = 1,2…}
$$
(上面为 条件概率公式 (conditional probability) )
为在 ${Y=y_j}$ 条件下,随机变量 $X$ 的条件分布律.
普通的条件概率和二元离散型随机变量的条件概率
两个事件 $A,B$ 的条件概率: 若 $P(A) > 0$, 考虑条件概率 $P(B|A)$
对于二元离散型变量 $(X,Y)$ 的条件概率, 已知其分布律为:
$$
\displaylines{P(X=x_i, Y=y_j) = p_{ij} , \ \ i,j = 1,2…}
$$
若 $P(Y=y_j) = p_{\bullet j} > 0$, 考虑条件概率 $P(X=x_i | Y=y_j)$
二元随机变量的分布函数
联合分布函数
分布函数的值都是概率的累加.
定义
设 $(X,y)$ 是二元随机变量,对于任意实数 $x,y$, 二元函数:
$$
\displaylines{F(x,y) = P{(X \le x) \cap (Y \le y)} \newline~ \newline
\overset{记成}{=} P(X \le x, Y \le y)}
$$
称为二元随机变量 $(X,Y)$ 的 联合分布函数
性质
- $F(x,y)$ 关于 $x,y$ 单调不减
- $0 \le F(x,y) \le 1, \ F(+\infty, +\infty) = 1$
- $F(x,y)$ 关于 $x,y$ 右连续
边际分布函数
二元随机变量 $(X,Y)$ 的边际分布函数:
$$
\displaylines{F_X(x) = F(x,+\infty) = P(X \le x) = P(X \le x, Y \le +\infty)\newline~ \newline
F_Y(y) = F(+\infty,y) = P(Y \le y) = P(X \le +\infty, Y \le y)}
$$
( 下标 表明括号里的是谁的值,如 $F_X(x)$, 下标是 $X$, 括号里的 $x$ 代表的就是 $X$ 的值)
条件分布函数
定义
若 $P(Y=y) > 0$, 则在 ${Y=y}$ 条件下, $X$ 的条件分布函数为:
$$
\displaylines{F(x|y) = P(X \le x | Y = y) = \frac{P(X \le x, Y = y)}{P(Y=y)}}
$$
二元连续型随机变量
离散型称 – 分布函数
连续型称 – 密度函数
密度函数就是被积分的函数.
都有:
- 联合
- 边际
- 条件
联合概率密度函数
定义
对于二元随机变量 $(X,Y)$ 的分布函数 $F(x,y)$, 如果存在非负函数 $f(x,y)$, 使对于任意 $x,y$ 有:
$$
\displaylines{F(x,y) = \int_{- \infty}^y \int_{- \infty}^xf(\mu,v) d\mu dv}
$$
称 $(X,Y)$ 为二元 连续型 随机变量.
称 $f(x,y)$ 为二元随机变量 (X,Y) 的 联合概率密度函数
性质
- $f(x,y) \ge 0$
- $\int_{-\infty}^{+\infty} \int_{-\infty}^{+\infty} f(x,y) dx dy = 1$
- $$
\displaylines{ \frac{\partial ^2 F(x,y)}{\partial x \partial y} = f(x,y)}
$$
边际概率密度函数
$$
\displaylines{f_X(x) = \int_{-\infty}^{+\infty}f(x,y) dy \newline~ \newline
f_Y(y) = \int_{-\infty}^{+\infty}f(x,y) dx}
$$
( 下标 表明括号里的是谁的值,如 $f_X(x)$, 下标是 $X$, 括号里的 $x$ 代表的就是 $X$ 的值确定)
条件概率密度函数
在 ${ Y = y }$ 条件下X 的条件密度函数为
$$
\displaylines{f_{X|Y}(x|y) = \frac{f(x,y)}{f_Y(y)} , \ \ f_Y(y) > 0}
$$
在 ${X = x }$条件下,Y的条件密度函数为
$$
\displaylines{f_{X|Y}(x|y) = \frac{f(x,y)}{f_Y(y)} , \ \ f_Y(y) > 0}
$$
性质
- $f_{X|Y}(x|y) \ge 0$
- $\int_{-\infty}^{+\infty} f_{X|Y}(x|y) dx = 1$
- $P{a < X < b|Y= y} = \int_a^b f_{X|Y}(x|y) dx$
- $f(x,y) = f_{X|Y}(x|y)f_Y(y) = f_X(x) f_{X|Y}(x|y)$
二元均匀分布与二元正态分布
若二元随机变量(X,Y)在二维有界区域上取值,且具有概率密度函数:
$$
\displaylines{f(x,y) =
\begin{cases}
\frac{1}{D 的面积}, \ \ (x,y) \in D \newline~ \newline
0, \ \ 其他
\end{cases}}
$$
则称 $(X,Y)$ 在D上服从均匀分布
被积分的函数是常量,积分的值也就均匀变化.

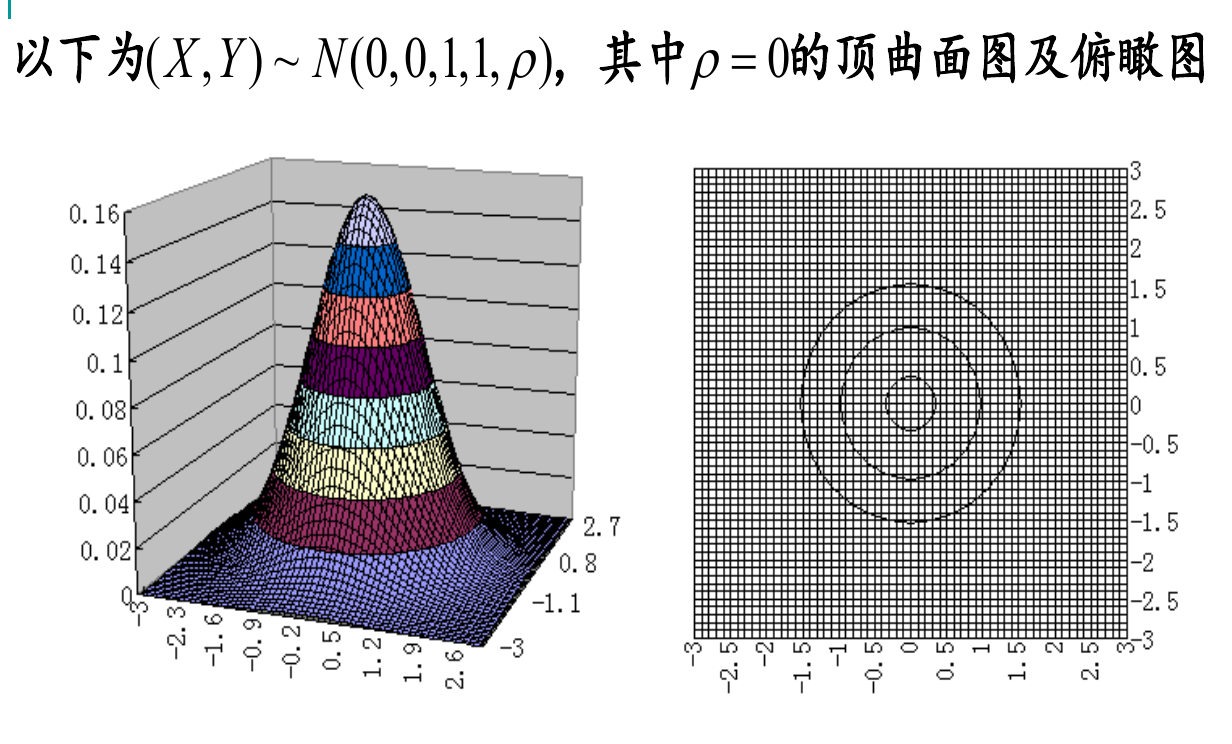
随机变量的独立性
同样是,交集可以换成概率的乘积,就说明独立.
$$
\displaylines{P(X \le x, Y \le y) = P(X \le x) P(Y \le y) \newline~ \newline
即,\ \ F(x,y) = F_X(x) F_Y(y)}
$$
称随机变量 $X,Y$ 相互独立.
若 $( X , Y )$ 是离散型随机变量:
$$
\displaylines{P(X = x_i, Y = y_j) = P(X = x_i) P(Y = y_j) \newline~ \newline
即, \ \ p_[ij] = p_{i \bullet} p_{\bullet j}}
$$
若 $( X , Y )$ 是连续型随机变量:
$$
\displaylines{f(x,y) = f_X(x)f_Y(y)}
$$
注意 n 元随机变量的一些概念和结果以及多元随机变量相互独立
卷积公式
当 X 与 Y 相互独立时:
$$
\displaylines{f_Z(z) = \int_{-\infty}^{+\infty} f_X(z-y)f_Y(y) dy = \int_{-\infty}^{+\infty} f_X(x) f_Y(z-x) dx}
$$
第四章 随机变量的数字特征
数学期望
数学期望简称 期望, 又叫 均值.
但这个均值不是所有结果的平均值,
其计算是:
$$
\displaylines{\sum 随机变量的值\ x \times \ 概率\ p \newline~ \newline
即 \newline~ \newline
P(X = x_k) = p_k \ \ k=1,2,… \newline~ \newline
E(X) = \sum_{k=1}^{+\infty} x_k p_k}
$$
有点像面积计算,概率是高,值是底.
当 $X$ 是连续型随机变量时,可用概率密度函数计算, 概率密度函数 $f(x)$ 上的一个点的值就是一个样本点的概率, 而 $x$ 就是这个样本点的值,因此,期望的计算为:
$$
\displaylines{E(X) = \int_{-\infty}^{+\infty} xf(x) dx}
$$
简单的图示

随机变量函数的数学期望
即,此时的变量是一个函数,而不是一个单变量, 求 $E(Y)$, 而 $Y = g(X)$.
当 $X$ 是离散型随机变量时
分布律为:
$$
\displaylines{P(X = x_k) = p_k, \ \ k=1,2,…}
$$
求期望为:
$$
\displaylines{E(Y) = E[g(X)] = \sum_{k=1}^{\infty} g(x_k) p_k}
$$
可以看出,此时和概率相乘的是 $X$ 的表达式.
当 $X$ 是连续型随机变量时, 密度函数为 $f(x)$
求期望为
$$
\displaylines{E(Y) = E(g(X)) = \int_{-\infty}^{+\infty} g(x) f(x) dx}
$$
推广到二元及多元
二元离散型随机变量 $(X,Y)$ 的分布律为:
$$
\displaylines{P(X= x_i, Y=y_j)= p_{ij}, \ \ i,j=1,2,… \newline~ \newline
E(Z) = E[h(X,Y)] = \sum_{i=1}^\infty \sum_{j=1}^\infty h(x_i, y_j) p_{ij}}
$$
二元连续型随机变量 $(X,Y)$ 的密度函数 $f(x,y)$
$$
\displaylines{E(Z) = E(h(X,Y)) = \int_{-\infty}^{+\infty} \int_{-\infty}^{+\infty} h(x_i, y_j) f(x,y) dx dy}
$$
数学期望的特性
- 设 $C$ 是常数, 则有 $E(C) = C$
- 设 X 是随机变量,C 是常数,则有 $E(CX) = CE(X)$
- 设 X,Y 是随机变量, 则有 $E(X+Y) = E(X) + E(Y)$
- 当 X,Y 独立时, 有 $E(XY) = E(X) E(Y)$
推广
$$
\displaylines{E(c_0 + \sum_{i=1}^n c_i X_i) = c_0 + \sum_{i=1}^n E(X_i)}
$$
- 设 $X,Y$ 是相互独立随机变量, 则有
$$
\displaylines{E(XY) = E(X)E(Y)}
$$
推广
$$
\displaylines{E(\prod_{i=1}^n X_i) = \prod_{i=1}^n E(X_i)}
$$
其中, $X_i, \ \ i=1,…,n$ 相互独立.
证明
C 是常数:
$$
\displaylines{P(X=C) = 1, \ \ E(X) = E(C) = 1 \times C = C}
$$
X 为连续型随机变量:
$E(CX)$ 相当于此时的变量值为 $Cx$.
$$
\displaylines{E(CX) = \int_{-\infty}^{+\infty} Cxf(x)dx = C\int_{-\infty}^{+\infty} xf(x)dx = CE(X)}
$$
$E(X+Y)$ 相当于此时的变量值为 $x+y$. 每一样本点的概率值为 $f(x,y)$
$$
\displaylines{E(X+Y) = \int_{-\infty}^{+\infty}\int_{-\infty}^{+\infty} (x+y)f(x,y) dx dy \newline~ \newline
= \int_{-\infty}^{+\infty}\int_{-\infty}^{+\infty} xf(x,y)dxdy + \int_{-\infty}^{+\infty}\int_{-\infty}^{+\infty} yf(x,y)dxdy \newline~ \newline
= E(X) + E(Y)}
$$
$E(XY)$ 相当于此时的变量值为 $xy$
$$
\displaylines{\int_{-\infty}^{+\infty}\int_{-\infty}^{+\infty} xyf(x,y)dxdy \newline~ \newline
= \int_{-\infty}^{+\infty}\int_{-\infty}^{+\infty} xy f_X(x) f_Y(y) dxdy \newline~ \newline
= \int_{-\infty}^{+\infty} xf_X(x)dx \int_{-\infty}^{+\infty}yf_Y(y)dy \newline~ \newline
= E(X)E(Y)}
$$
此时的 $E(X)\ \ 和\ \ E(Y)$ 都是一元的.
技巧
将 X 分解成数个随机变量之和,然后利用随机变量和的数学期望等于随机变量数学期望这和来求数学期望.
方差 Variance
方差用于描述偏离程度.
也是求期望,只不过这时的变量值为 $[ x_i - E(X) ]^2$, 概率值为 $p_i$ 或 $f(x)$
定义
$$
\displaylines{Var(X) = E{[X-E(X)]^2}}
$$
方差 记为 $Var(X)$ 或 $D(X)$
将 $\sqrt{Var(X)}$ 记为 $\sigma (X)$, 称为 $X$ 的 标准差或均方差.
对于离散型随机变量 X
其分布律为: $P(X=x_i) = p_i, \ \ i=1,2,…$
$$
\displaylines{Var(X) = \sum_{i=1}^\infty [ x_i - E(X) ]^2 p_i}
$$
对于连续型随机变量 X
其密度函数为 $f(x)$
$$
\displaylines{Var(X) = \int_{-\infty}^{+\infty} [x-E(X)]^2 f(x)dx}
$$
心得 :
离散型随机变量 X 的概率值用 分布律 描述.
连续型随机变量 X 的概率值用 密度函数 描述.
方差计算公式
$$
\displaylines{Var(X) = E(X^2) - [E(X)]^2}
$$
推导
$$
\displaylines{Var(X) = E{ [ X-E(X) ]^2 } \newline~ \newline
= E{ X^2 - 2XE(X) + [E(X)]^2 } \newline~ \newline
= E(X^2) - E(2XE(X)) + E([E(X)]^2) \newline~ \newline
= E(X^2) - \int_{-\infty}^{+\infty} 2xE(X) f(x)dx + \int_{-\infty}^{+\infty} [E(X)]^2 f(x)dx \newline~ \newline
= E(X^2) -2\int_{-\infty}^{+\infty} xf(x)dx \int_{-\infty}^{+\infty} xf(x)dx + \int_{-\infty}^{+\infty} f(x)dx \int_{-\infty}^{+\infty} xf(x)dx \int_{-\infty}^{+\infty} xf(x) dx \newline~ \newline
= E(X^2) - 2[E(X)]^2 + [E(X)]^2 \newline~ \newline
= E(X^2) - [E(X)]^2}
$$
推导过程中可以发现, $E(XE(X)) = E(E(X)^2) = [E(X)]^2$
性质
- 设 C 是常数, 则 $Var(C) = 0$
推导
$$
\displaylines{Var(C) = E{[ C - E(C) ]^2} = E{[ C - C ]^2} = 0}
$$
- 设 X 是随机变量,C是常数,则有 $Var(CX) = C^2 Var(X)$
推导
$$
\displaylines{Var(CX) = E((CX)^2) - [E(CX)]^2 \newline~ \newline
= C^2 E(X^2) - C^2 [E(X)]^2 \newline~ \newline
= C^2 {E(X^2) - [E(X)]^2} \newline~ \newline
C^2 Var(X)}
$$
- 设 $X,Y$ 是两个随机变量,则有:
$$
\displaylines{Var(X+Y) = Var(X) + Var(Y) + 2E{[X-E(X)][Y-E(Y)]}}
$$
若 $X,Y$ 相互独立,则有 $Var(X+Y) = Var(X) + Var(Y)$
推广
$$
\displaylines{Var(aX + bY + c) = a^2 Var(X) + b^2 Var(Y) \newline~ \newline
Var(c_0 + \sum_{i=1}^n c_i X_i) = \sum_{i=1}^n c_i^2 Var(X_i)}
$$
- $Var(X) = 0 \Leftrightarrow P(X=C)=1, \ \ 即 E(X)=xp = C P(X=C) = C \times 1 = C$
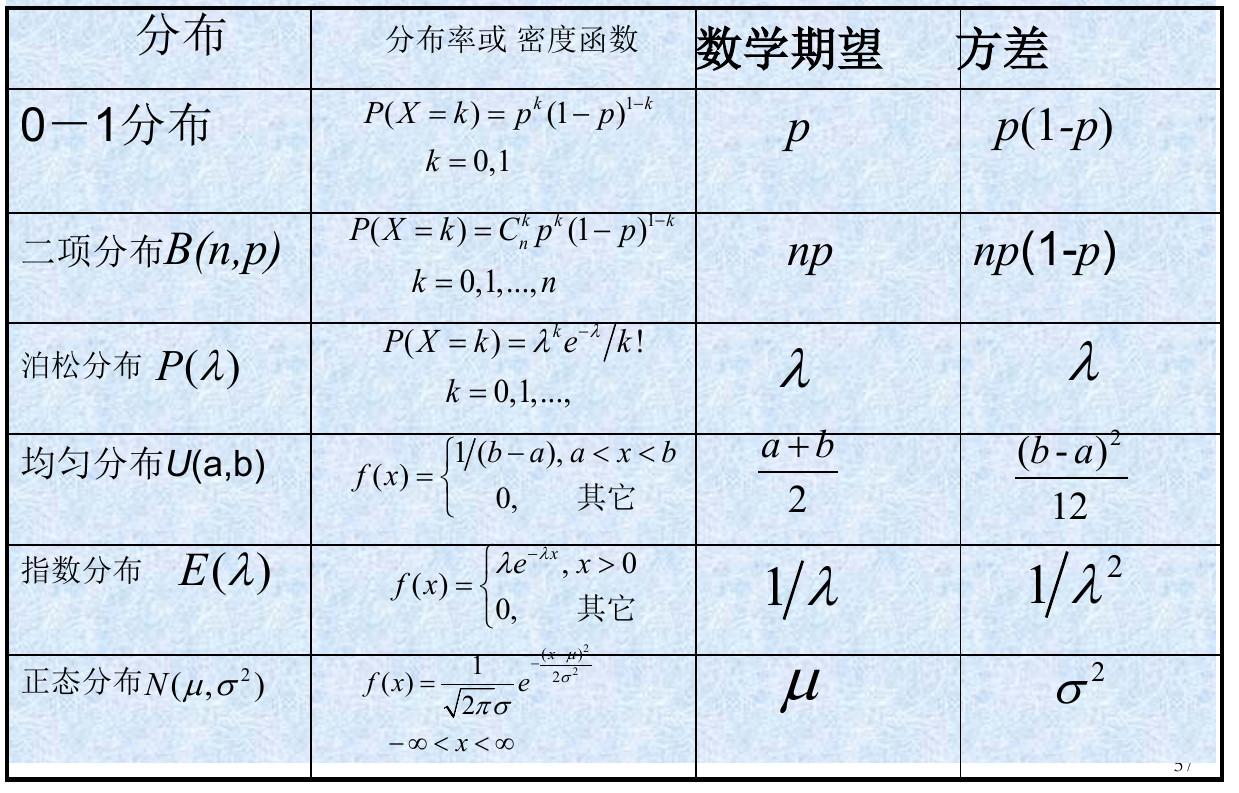
几种常见分布的期望和方差
独立的 n 个正态变量的线性组合仍服从正态分布

标准化变量
定义
设随机变量 X 具有:
- 数学期望 $E(X) = \mu$
- 方差 $Var(X) = \sigma^2 \ne 0$
记 $X^\ast = \frac{X- \mu}{\sigma}$ 则称 $X^\ast$ 为 $X$ 的 标准化变量
性质
- $E(X^\ast) = 0$
- $Var(X^\ast) = 1$
推导
$$
\displaylines{E(X^\ast) = \frac{1}{\sigma} E(X - \mu) = \frac{1}{\sigma}[E(X) - \mu] \newline~ \newline
\because E(X) = \mu \newline~ \newline
\therefore E(X^\ast) = 0 \newline~ \newline
also \newline~ \newline
Var(X^\ast) = E(X^{\ast^2}) - [E(X^\ast)]^2 = E[( \frac{X - \mu}{\sigma} )^2] \newline~ \newline
= \frac{1}{\sigma^2} E[(X- \mu)^2] = \frac{\sigma^2}{\sigma^2} = 1}
$$
协方差与相关系数
协方差
定义
$E{[X-E(X)][Y-E(Y)]}$ 称为随机变量 X 与 Y 的 协方差 , 记为 $Cov(X,y)$, 即:
$$
\displaylines{Cov(X,Y) = E{[X-E(X)][Y-E(Y)]}}
$$
计算公式
$$
\displaylines{Cov(X,Y) = E(XY) - E(X)E(Y)}
$$
和方差相关的性质
$$
\displaylines{Var(X+Y) = Var(X) + Var(Y) + 2Cov(X,Y)}
$$
协方差的性质
- $Cov(X,Y) = Cov(Y,X)$
- $Cov(X,X) = Var(X)$
- $Cov(aX,bY) = ab \cdot Cov(X,Y)$, 其中 $a,b$ 为两个实数
- $Cov(X_1 + X_2, Y) = Cov(X_1, Y) + Cov(X_2, Y)$
- 当 $Var(X)Var(Y) \ne 0$ 时,有 $(Cov(X,Y))^2 \le Var(X)Var(Y)$
相关系数
定义
$\rho_{XY} = \frac{Cov(X,Y)}{\sqrt{Var(X)Var(Y)}}$ 称为 X 与 Y 的 相关系数 .
$$
\displaylines{\pho_{XY} = Cov( \frac{X - E(X)}{\sqrt{Var(X)}}, \frac{X - E(Y)}{\sqrt{Var(Y)}} )}
$$
性质
- $\left\vert \rho_{XY} \le 1 \right\vert$
- $\left\vert \rho_{XY} = 1 \right\vert \Leftrightarrow$ 存在常数 a,b, 使 $P(Y=a+bX) = 1$, $\rho_{XY} = 1$ 时, $b > 0$; $\rho = -1$ 时, $b < 0$
相关系数 $\rho_{XY}$ 是一个用来表征 $X,Y$ 之间 线性关系紧密程度 的量。
当 $\left\vert \rho_{XY} \right\vert$ 较大时,表明 X,Y 线性关系的程度较好.
当 $\rho_{XY} > 0$ 时,称 X 与 Y 为 正相关
当 $\rho_{XY} < 0$ 时,称 X 与 Y 为 负相关
不相关或零相关
定义
$\rho_{XY} = 0$ 称 X 与 Y 不相关或零相关
等价条件有:
- $Cov(X,Y) = 0$
- $E(XY) = E(X) E(Y)$
- $Var(X+Y) = Var(X) + Var(Y)$
X,Y 相互独立,两者一定不相关.
X,Y 不相关,两者不一定相互独立.
其他数字特征


多元随机变量的数字特征
第五章 大数定律和中心极限定理
依概率收敛
这里讲的是,当事件次数极多时 (即大数), 概率会趋于一个常量.
随机变量序列 $Y_1, Y_2, Y_3,…,$ 若存在某常数 c, 使得 $\forall \epsilon, $ 均有
$$
\displaylines{\lim_{n \rightarrow + \infty} P{ \left\vert Y_n -c \right\vert \ge \epsilon} = 0}
$$
即 ${Y_n, n \ge 1}$ 依概率收敛于常数 c.
$\left\vert Y_n - c \right\vert \ge \epsilon$ 的含义是,距常数 c 大小相差 $\epsilon$ 的距离存在随机变量值.
性质
若 $X_n \overset{P}{\longrightarrow} a, Y_n \overset{P}{\longrightarrow} b,$ g 在 $(a,b)$ 连续,则
$$
\displaylines{g(X_n,Y_n) \overset{P}{\longrightarrow} g(a,b)}
$$
马尔可夫不等式和切比雪夫不等式
马尔可夫不等式
设随机变量 Y 的 k 阶矩存在 ( $k \ge 1$ ), 即 $E(X^k)$ 存在,则对任意 $\epsilon > 0$ 都有:
$$
\displaylines{P{ \left\vert Y \right\vert \ge \epsilon } \le \frac{E( \left\vert Y \right\vert ^k )}{\epsilon^k}}
$$
成立.
等价于:
$$
\displaylines{P{ \left\vert Y \right\vert < \epsilon } \ge 1 - \frac{E( \left\vert Y \right\vert ^k )}{\epsilon^k}}
$$
证明
对于任意 $\epsilon > 0$, 令
$$
\displaylines{Z =
\begin{cases}
\epsilon, 当 \left\vert Y \right\vert \ge \epsilon \newline~ \newline
0, 当 \left\vert Y \right\vert < \epsilon
\end{cases}}
$$
则 $Z \le \left\vert Y \right\vert \ \Rightarrow \ Z^k \le \left\vert Y \right\vert ^k \Rightarrow \ E(Z^k) \le E( \left\vert Y \right\vert ^k )$
$$
\displaylines{\because E(Z^k) = \epsilon^k P{ \left\vert Y \right\vert \ge \epsilon } \newline~ \newline
\therefore P{ \left\vert Y \right\vert \epsilon } = \frac{E(Z^k)}{\epsilon^k} \le \frac{E( \left\vert Y \right\vert ^k )}{\epsilon^k}}
$$
切比雪夫不等式
设 X 的方差 $Var(X)$ 存在,则对于任意 $\epsilon > 0$, 都有:
$$
\displaylines{P{ \left\vert X - E(X) \right\vert \ge \epsilon } \le \frac{Var(X)}{\epsilon^2}}
$$
等价于:
$$
\displaylines{P{ \left\vert X - E(X) \right\vert < \epsilon } \ge 1 - \frac{Var(X)}{\epsilon^2}}
$$
几个大数定律
弱大数定律
设 $Y_1, …, Y_n,…$ 为一个随机变量序列,若存在常数序列,使得当
$$
\displaylines{n \rightarrow +\infty, \ \frac{1}{n} \sum_{i=1}^n Y_i - c_n \overset{P}{\longrightarrow} 0 \newline~ \newline
即\ \forall \epsilon > 0, 有 \newline~ \newline
\lim_{n \rightarrow \infty} P{ \left\vert \frac{1}{n} \sum_{i=1}^n Y_i - c_n \right\vert \ge \epsilon } = 0}
$$
则称 ${ Y_i, i \ge 1 }$ 服从弱大数定律.
当 $c_n = c, \ n=1,2,…$ 时,可写为:
$$
\displaylines{ \frac{1}{n} \sum_{i=1}^n Y_i \overset{P}{\longrightarrow} c, n \rightarrow + \infty}
$$
切比雪夫大数定律
设 $X_1, X_2, …, X_n,…$ 相互独立,具有相同的数学期望 $\mu$ 和相同的方差 $\sigma^2$, 则当:
$$
\displaylines{n \rightarrow + \infty \ 时, \ \frac{1}{n} \sum_{k=1}^n \overset{P}{\longrightarrow} \mu}
$$
证明
$$
\displaylines{\because E( \frac{1}{n} \sum_{i=1}^n X_i ) = \frac{1}{n} \sum_{i=1}^n E(X_i) = \mu \newline~ \newline
Var( \frac{1}{n} \sum_{i=1}^n X_i ) = \frac{1}{n^2} Var( \sum_{i=1}^n X_i ) = \frac{1}{n^2} \sum_{i=1}^n Var(X_i) = \frac{\sigma^2}{n} \newline~ \newline
利用切比雪夫不等式: \newline~ \newline
0 \le P( \left\vert \frac{1}{n} \sum_{i=1}^n X_i - \mu \right\vert \ge \epsilon ) \le \frac{Var( \frac{1}{n} \sum_{i=1}^n X_i )}{\epsilon^2} = \frac{\sigma^2}{n \epsilon^2} \rightarrow 0}
$$
辛钦大数定理
设 $X_1, X_2, …, X_n,…$ 独立同分布:
$$
\displaylines{E(X_i) = \mu, \newline~ \newline
则当 \ \ n \rightarrow + \infty \newline~ \newline
\frac{1}{n} \sum_{i=1}^n X_i \overset{P}{\longrightarrow} \mu}
$$
推论
设 $X_1, X_2, …, X_n,…$ 独立同分布, 若 $h(x)$ 是连续函数, $E(h(X_1)) = a$ 存在,则当:
$$
\displaylines{n \rightarrow + \infty \newline~ \newline
\frac{1}{n} \sum_{i=1}^n h(X_i) \overset{P}{\longrightarrow} a}
$$
贝努利大数定理
设 $n_A$ 为 n 重贝努利试验中事件 A 发生的次数,并记事件 A 在每次试验中发生的概率为 p, 则有:
$$
\displaylines{当 n \rightarrow + \infty \ 时 \newline~ \newline
\frac{n_A}{n} \overset{P}{\longrightarrow} p}
$$
证明
可利用切比雪夫不等式.
中心极限定理
独立同分布的中心极限定理
设 $X_1, X_2, …, X_n,…$ 独立同分布:
$$
\displaylines{E(X_i) = \mu,\ \ Var(X_i) = \sigma^2 \newline~ \newline
则对任意实数 x \newline~ \newline
\lim_{n \rightarrow \infty} P( \frac{\sum_{i=1}^n X_i - n \mu}{\sqrt{n} \sigma} \le x ) = \int_{- \infty}^x \frac{1}{\sqrt{2 \pi}} e^{- \frac{t^2}{2}} dt = \phi (x)}
$$
n 充分大时:
$$
\displaylines{\sum_{i=1}^n X_i \overset{近似}{\sim} N(n \mu, n \sigma^2) \newline~ \newline
\frac{1}{n} \sum_{i=1}^n X_i \overset{近似}{\sim} N(\mu, \frac{\sigma^2}{n})}
$$
推论 棣莫弗–拉普拉斯中心极限定理
设 $n_A$ 为 n 重贝努利试验中事件 A 发生的次数, $P(A) = p(0 < p < 1)$, 则对任何实数 x, 有:
$$
\displaylines{\lim_{n \rightarrow +\infty} P( \frac{n_A - np}{\sqrt{np (1-p)}} \le x) = \int_{-\infty}^{x} \frac{1}{\sqrt{2 \pi}} e^{- \frac{t^2}{2}} dt = \phi (x) \newline~ \newline
即,\ \ B(n,p) \overset{近似}{\sim} N(np,np(1-p))}
$$
第六章 统计量与抽样分布
随机样本与统计量
几个概念:
- 总体: 研究对象的全体
- 个体: 总体中的成员
- 总体的容量: 总体中包含的个体数
- 有限总体: 容量有限的总体
- 无限总体: 容量无限的总体,通常将容量非常大的总体也按无限总体处理
指标 X 看作是 随机变量.
有时把 X 称为总体 (X 就指代研究的对象)
假设 X 的分布函数为 $F(x)$, 也称 $F(x)$ 为总体.
从总体中被抽取的部分个体叫做总体的一个 样本
几个概念:
- 随机样本: 从总体中随机地取n个个体, 称为一个随机样本
- 简单随机样本: 满足以下两个条件的随机样本(X1,X2,…,Xn)称为容量是n的简单随机样本
- 代表性: 每个Xi与X同分布
- 独立性: X1,X2,…,Xn是相互独立的随机变量
获取简单随机样本的方式
有限总体 $\rightarrow$ 放回抽样.
总体容量大 $\rightarrow$ 不放回抽样近似.
无限总体,不放回抽样.
几个概念:
- 统计量: 样本的不含任何未知参数的函数
- 常用统计量:
- 样本均值 $\overline{X} = \frac{1}{n} \sum_{i=1}^n X_i$
- 样本方差 $S^2 = \frac{1}{ n - 1 }\sum_{i=1}^n (X_i - \overline{X})^2$
- 样本矩
- k 阶矩: $A_k = \frac{1}{n} \sum_{i=1}^n X_i^k \ \ (k = 1,2,…)$
- k 阶中心矩: $B_k = \frac{1}{n}\sum_{i=1}^n (X_i - \overline{X})^k \ \ (k = 1,2,…)$
$x^2$ 分布 t 分布 F 分布
$x^2$ 分布
定义
设随机变量 $X_1, X_2, …, X_n$ 相互独立, $X_i \sim N(0,1)\ \ (i=1,2,…,n)$, 则称:
$$
\displaylines{X^2 = \sum_{i=1}^n X_i^2}
$$
为服从 自由度为 n 的 $X^2$ 分布.
记为 $X^2 \sim X^2 (n)$
(自由度指独立变量个数. 独立了,也就自由了)
$x^2$ 分布 的概率密度函数
见书.
性质
- 设 $X^2 \sim X^2(n)$ 则有 $E(X^2) = n, \ Var(X^2) = 2n$
- 设 $Y_i \sim X^2(n_i), \ i=1,2$, 且 $Y_1, Y_2$ 相互独立,则有 $Y_1 + Y_2 \sim X^2(n_1 + n_2)$
推广
若 $Y_i \sim X^2(n_i), \ i=1,2,…m$, $Y_1, Y_2,… Y_m$ 相互独立,则有 $\sum_{i=1}^m Y_i \sim X^2(\sum_{i=1}^m n_i)$
t 分布
设 $X \sim N(0,1), \ Y \sim X^2(n)$, 并且假设 X,Y 相互独立。
则称:
$$
\displaylines{T = \frac{X}{\sqrt{ \frac{Y}{n} }}}
$$
服从自由度为 n 的 t 分布.
记为 $T \sim t(n)$.
密度函数等见书.
F 分布
设 $X \sim \chi^2(n_1), \ Y \sim \chi^2(n_2)$, 且 X,Y 独立,则称:
$$
\displaylines{随机变量F = \frac{ \frac{X}{n_1} }{ \frac{Y}{n_2} }}
$$
服从自由度为 $(n_1, n_2)$ 的 F 分布.
记为 $F \sim F(n_1, n_2)$.
其中 $n_1$ 称为第一自由度, $n_2$ 称为第二自由度.
性质
$F \sim F(n_1, n_2) \ \ 则 \ F^{-1} \sim F(n_2,n_1)$
密度函数等见书.
正态总体下的抽样分布
设$X_1, X_2, …, X_n$ 为来自正态总体 $N(\mu, \sigma^2)$ 的简单随机样本, $\overline{X}$ 是样本均值, $S^2$ 是样本方差, 则有:
$$
\displaylines{\overline{X} \sim N(\mu, \frac{\sigma^2}{n})}
$$
- $\frac{(n-1)S^2}{\sigma^2} \sim \chi^2(n-1)$
- $\overline{X}$ 与 $S^2$ 相互独立
第七章 参数估计
参数: 反映总体某方面特征的量.
参数估计: 当总体的参数未知时, 需要利用样本其给出估计.
两类参数估计方法:
- 点估计
- 区间估计
参数的点估计
设总体 X 有未知参数 $\theta$.
$X_1, X_2, …, X_n$ 是 X 的简单随机样本.
构造合适的统计量 $\hat{\theta} = \hat{\theta}($X_1, X_2, …, X_n$)$ 用来估计未知参数 $\theta$, 称 $\hat{\theta}$ 为参数 $\theta$ 的 点估计量
当给定样本观察值 $X_1, X_2, …, X_n$ 时,称 $\hat{\theta} = \hat{\theta}($X_1, X_2, …, X_n$)$ 为参数 $\theta$ 的 点估计值 .
常用的点估计法:
- 矩阵估计法
- 极大似然估计法
矩阵估计法
感觉有点复杂,这里先不记.
极大似然估计法
就是判断那一个结果更合理. 这里就是大的更合理.
这个例子很好说明.

估计量的评选原则
用于评判估计量的好坏.
第八章 假设检验
8.1 假设检验的基本思想
包括:
- 参数检验
- 非参数检验
假设的内容 , 设:
- 原假设 (零假设, the null hypotheses) $H_0$ (称为零假设可能就是这个 $H_0$ 的缘故)
- 备择假设 (对立假设, the alternative hypotheses) $H_1$