my $megalithFile = $ARGV[0]; my $siteName = $ARGV[1];
对于 delimiter character 的方式
存储的数据如:
1
Stonehenge:Wiltshire:SU 123400:Stone Circle and Henge:The most famous stone circle
处理数据的代码如:
1 2 3 4 5 6 7 8 9 10 11 12 13
### Scan through all the entries for the desired site while ( <MEGADATA> ) { ### Remove the newline that acts as a record delimiter chop; ### Break up the record data into separate fields ( $name, $location, $mapref, $type, $description ) = split( /:/, $_ ); ### Test the sitename against the record's name if ( $name eq $siteName ) { $found = $.; # $. holds current line number in file last; } }
这里有判断找到数据的行号的代码.
这种方式的缺陷: 若数据中含有 delimiter character 如 :, 则会产生错误的分割.
对于固定长度 fields 的方式
存储的数据如:
1 2 3 4 5 6 7
Field Required Bytes ----- -------------- Name 64 Location64 Map Reference16 Type32 Description 256
利用 unpack 来处理处理:
1 2 3 4
### Break up the record data into separate fields ### using the data sizes listed above ( $name, $location, $mapref, $type, $description ) = unpack( "A64 A64 A16 A32 A256", $_ );
其缺点是需要确定长度. 且会使用很多无用的 space.
2.4.2 插入数据
将数据插入到一个 flat-file database 一般比较直接, 将新数据放到 data file 的末尾即可.
my $megalithFile = $ARGV[0]; my $siteName = $ARGV[1]; my $siteLocation = $ARGV[2]; my $siteMapRef = $ARGV[3]; my $siteType = $ARGV[4]; my $siteDescription = $ARGV[5];
### Open the data file for concatenation, and die upon failure open MEGADATA, ">>$megalithFile" ordie"Can't open $megalithFile for appending: $!\n"; ### Create a new record my $record = join( ":", $siteName, $siteLocation, $siteMapRef, $siteType, $siteDescription ); ### Insert the new record into the file print MEGADATA "$record\n" ordie"Error writing to $megalithFile: $!\n"; ### Close the megalith data file close MEGADATA ordie"Error closing $megalithFile: $!"; print"Inserted record for $siteName\n"; exit;
while ( <MEGADATA> ) { ### Quick pre-check for maximum performance: ### Skip the record if the site name doesn't appear as a field nextunless m/^\Q$siteName:/; ### Break up the record data into separate fields ### (we let $description carry the newline for us) my ( $name, $location, $mapref, $type, $description ) = split( /:/, $_ ); ### Skip the record if the site name doesn't match. (Redundant after the ### reliable pre-check above but kept for consistency with other examples.) nextunless $siteName eq $name; ### We've found the record to update, so update the map ref value $mapref = $siteMapRef; ### Construct an updated record $_ = join( ":", $name, $location, $mapref, $type, $description ); } continue { ### Write the record out to the temporary file print TMPMEGADATA $_ ordie"Error writing $tempFile: $!\n"; }
注意 next 的使用.
这里的 while ... continue 语句, 每一次执行完 while 循环体之后, 都会执行 continue 中的代码.
对于固定长度的类型, 其处理为:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
### Scan through all the records looking for the desired site while ( <MEGADATA> ) { ### Quick pre-check for maximum performance: ### Skip the record if the site name doesn't appear at the start nextunless m/^\Q$siteName/; ### Skip the record if the extracted site name field doesn't match nextunlessunpack( "A64", $_ ) eq $siteName; ### Perform in-place substitution to upate map reference field substr( $_, 64+64, 16) = pack( "A16", $siteMapRef ); } continue { ### Write the record out to the temporary file print TMPMEGADATA $_ ordie"Error writing $tempFile: $!\n"; }
2.4.4 删除数据
其和前面的操作类似, 只不过, 不将要删除的部分写回文件即可:
1 2 3 4 5 6 7 8 9 10 11 12 13
### Scan through all the entries for the desired site while ( <MEGADATA> ) { ### Extract the site name (the first field) from the record my ( $name ) = split( /:/, $_ ); ### Test the sitename against the record's name if ( $siteName eq $name ) { ### We've found the record to delete, so skip it and move to next record next; } ### Write the original record out to the temporary file print TMPMEGADATA $_ ordie"Error writing $tempFile: $!\n"; }
对于 fixed-length data file:
1 2 3 4 5 6 7 8 9 10 11 12 13
### Scan through all the entries for the desired site while ( <MEGADATA> ) { ### Extract the site name (the first field) from the record my ( $name ) = unpack( "A64", $_ ); if ( $siteName eq $name ) { ### We've found the record to delete, so skip it and move to next record next; } ### Write the original record out to the temporary file print TMPMEGADATA $_ ordie"Error writing $tempFile: $!\n"; }
### Scan through all the entries for the desired site while ( <MEGADATA> ) { ### Quick pre-check for maximum performance: ### Skip the record if the site name doesn't appear nextunless m/\Q$siteName/; ### Evaluate perl record string to set $fields array reference my $fields; eval $_; dieif $@; ### Break up the record data into separate fields my ( $name, $location, $mapref, $type, $description ) = @$fields; ### Skip the record if the extracted site name field doesn't match nextunless $siteName eq $name; ### We've found the record to update ### Create a new fields array with new map ref value $fields = [ $name, $location, $siteMapRef, $type, $description ]; ### Convert it into a line of perl code encoding our record string $_ = Data::Dumper->new( [ $fields ], [ 'fields' ] )->Dump(); $_ .= "\n"; }
### Open the data file for reading, and die upon failure open MEGADATA, $ARGV[0] ordie"Can't open $ARGV[0]: $!\n"; print"Acquiring a shared lock..."; flock( MEGADATA, LOCK_SH ) ordie"Unable to acquire shared lock: $!. Aborting"; print"Acquired lock. Ready to read database!\n\n";
### Open the data file for appending, and die upon failure open MEGADATA, "+>>$ARGV[0]" ordie"Can't open $ARGV[0] for appending: $!\n"; print"Acquiring an exclusive lock..."; flock( MEGADATA, LOCK_EX ) ordie"Unable to acquire exclusive lock: $!. Aborting"; print"Acquired lock. Ready to update database!\n\n";
2.7 DBM 文件以及 BerkeleyDatabase Manager
DBM files 是存储管理层, 允许将信息以 pairs of strings, a key, and a value 的形式存储在文件中.
DBM files 是二进制文件, 其存储的 strings, key 信息也是二进制.
DBM files 有几种不同的形式 (括号里为扩展):
ndbm (NDBM_File)
db (DB_File)
gdbm (GDBM_File)
sdbm (SDBM_File)
odbm (ODBM_File)
注意一个模块 AnyDBM_File.
这些扩展将一个磁盘上的 DBM file 和 Perl 的一个 hash variable 联系在一起, 对 hash 的 fetch values into and out of the hash 操作就像是 getting them on and off the disk.
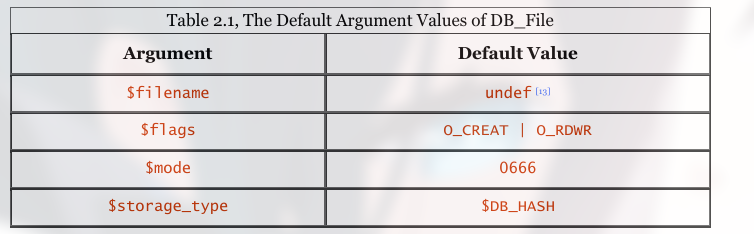
### Create the new database ... $db = tie %database, 'DB_File', "megaliths.dat" ordie"Can't initialize database: $!\n"; ### Acquire the file descriptor for the DBM file my $fd = $db->fd(); ### Do a careful open() of that descriptor to get a Perl filehandle open DATAFILE, "+<&=$fd"ordie"Can't safely open file: $!\n"; ### And lock it before we start loading data ... print"Acquiring an exclusive lock..."; flock( DATAFILE, LOCK_EX ) ordie"Unable to acquire exclusive lock: $!. Aborting"; print"Acquired lock. Ready to update database!\n\n";
由于某些原因, 最好这样写:
1 2 3
use Fcntl; # import O_EXLOCK, if available $db = tie %database, 'DB_File', "megaliths.dat", O_EXLOCK;
#!/usr/bin/perl -w # # ch02/DBM/simpleinsert: Creates a Berkeley DB, inserts some test data # and dumps it out again use DB_File; use Fcntl ':flock';
### Initialize the Berkeley DB my %database; my $db = tie %database, 'DB_File', "simpleinsert.dat", O_CREAT | O_RDWR, 0666 ordie"Can't initialize database: $!\n";
my $fd = $db->fd(); open DATAFILE, "+<&=$fd" ordie"Can't safely open file: $!\n"; print"Acquiring exclusive lock..."; flock( DATAFILE, LOCK_EX ) ordie"Unable to acquire lock: $!. Aborting"; print"Acquired lock. Ready to update database!\n\n";
### Insert some data rows $database{'Callanish I'} = "This site, commonly known as the \"Stonehenge of the North\" is in the form of a buckled Celtic cross."; $database{'Avebury'} = "Avebury is a vast, sprawling site that features, amongst other marvels, the largest stone circle in Britain. The henge itself is so large, it almost completely surrounds the village of Avebury."; $database{'Lundin Links'} = "Lundin Links is a megalithic curiosity, featuring 3 gnarled and immensely tall monoliths arranged possibly in a 4-poster design. Each monolith is over 5m tall.";
### Untie the database undef $db; untie %database;
### Close the file descriptor to release the lock close DATAFILE;
### Retie the database to ensure we're reading the stored data $db = tie %database, 'DB_File', "simpleinsert.dat", O_RDWR, 0444 ordie"Can't initialize database: $!\n";
### Only need to lock in shared mode this time because we're not updating ... $fd = $db->fd(); open DATAFILE, "+<&=$fd"ordie"Can't safely open file: $!\n"; print"Acquiring shared lock..."; flock( DATAFILE, LOCK_SH ) ordie"Unable to acquire lock: $!. Aborting"; print"Acquired lock. Ready to read database!\n\n";
### Dump the database foreachmy $key ( keys %database ) { print"$key\n", ( "="x ( length( $key ) + 1 ) ), "\n\n"; print"$database{$key}\n\n"; } ### Close the Berkeley DB undef $db; untie %database; ### Close the file descriptor to release the lock close DATAFILE; exit;
#!/usr/bin/perl -w # ch02/DBM/Megalith.pm: A perl class encapsulating a megalith package Megalith; use strict; use Carp;
### Creates a new megalith object and initializes the member fields. subnew{ my $class = shift; my ( $name, $location, $mapref, $type, $description ) = @_; my $self = {}; bless $self => $class;
### If we only have one argument, assume we have a string ### containing all the field values in $name and unpack it if ( @_ == 1 ) { $self->unpack( $name ); } else { $self->{name} = $name; $self->{location} = $location; $self->{mapref} = $mapref; $self->{type} = $type; $self->{description} = $description; } return $self; }
### Packs the current field values into a colon delimited record ### and returns it subpack{ my ( $self ) = @_; my $record = join( ':', $self->{name}, $self->{location}, $self->{mapref}, $self->{type}, $self->{description} ); ### Simple check that fields don't contain any colons croak "Record field contains ':' delimiter character" if $record =~ tr/:/:/ != 4;
return $record; }
### Unpacks the given string into the member fields subunpack{ my ( $self, $packedString ) = @_; ### Naive split...Assumes no inter-field delimiters
$database{'Callanish I'} = new Megalith( 'Callanish I', 'Western Isles', 'NB 213 330', 'Stone Circle', 'Description of Callanish I' )->pack();
### Dump the database foreach $key ( keys %database ) { ### Unpack the record into a new megalith object my $megalith = new Megalith( $database{$key} );
### And display the record $megalith->dump( ); }
2.7.3.3 对象访问方法
获取对象的属性, 不直接访问如:
1
print"Megalith Name: $megalith->{name}\n";
而是用一个方法, 如 getName():
1 2 3 4 5
### Returns the name of the megalith subgetName{ my ( $self ) = @_; return $self->{name}; }
### Build a referential hash based on the location of each monument $locationDatabase{'Wiltshire'} = \$database{'Avebury'}; $locationDatabase{'Western Isles'} = \$database{'Callanish I'}; $locationDatabase{'Fife'} = \$database{'Lundin Links'};
### Dump the location database foreach $key ( keys %locationDatabase ) { ### Unpack the record into a new megalith object my $megalith = new Megalith( ${ $locationDatabase{$key} } );
#!/usr/bin/perl -w # # ch02/DBM/dupkey1: Creates a Berkeley DB with the DB_BTREE mechanism and # allows for duplicate keys. We then insert some test # object data with duplicate keys and dump the final # database. use DB_File; use Fcntl ':flock'; use Megalith;
### Set Berkeley DB BTree mode to handle duplicate keys $DB_BTREE->{'flags'} = R_DUP;
### Remove any existing database files unlink'dupkey2.dat';
### Open the database up my %database; my $db = tie %database, 'DB_File', "dupkey2.dat", O_CREAT | O_RDWR, 0666, $DB_BTREE ordie"Can't initialize database: $!\n";
### Exclusively lock the database to ensure no one accesses it my $fd = $db->fd( ); open DATAFILE, "+<&=$fd" ordie"Can't safely open file: $!\n"; print"Acquiring exclusive lock..."; flock( DATAFILE, LOCK_EX ) ordie"Unable to acquire lock: $!. Aborting"; print"Acquired lock. Ready to update database!\n\n";
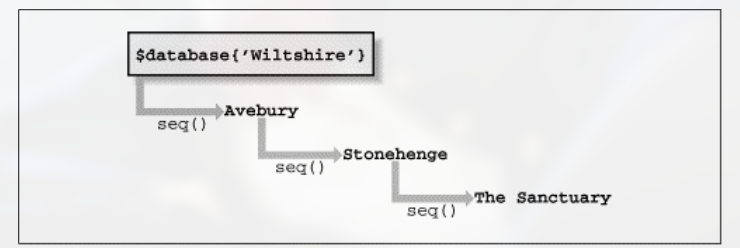
### Create, pack and insert some rows with duplicate keys $database{'Wiltshire'} = new Megalith( 'Avebury', 'Wiltshire', 'SU 103 700', 'Stone Circle and Henge', 'Largest stone circle in Britain' )->pack(); $database{'Wiltshire'} = new Megalith( 'Stonehenge', 'Wiltshire', 'SU 123 400', 'Stone Circle and Henge', 'The most popularly known stone circle in the world' )->pack(); $database{'Wiltshire'} = new Megalith( 'The Sanctuary', 'Wiltshire', 'SU 118 680', 'Stone Circle ( destroyed )', 'No description available' )->pack();
### Dump the database foreachmy $key ( keys %database ) { ### Unpack the record into a new megalith object my $megalith = new Megalith( $database{$key} );
### And display the record $megalith->dump( ); }
### Close the database undef $db; untie %database;
### Close the filehandle to release the lock close DATAFILE;
#!/usr/bin/perl -w # # ch02/mldbmtest: Demonstrates storing complex data structures in a DBM # file using the MLDBM module. use MLDBM qw( DB_File Data::Dumper ); use Fcntl;
### Remove the test file in case it exists already ... unlink'mldbmtest.dat';
### Create some megalith records in the database %database1 = ( 'Avebury' => { name =>'Avebury', mapref =>'SU 103 700', location =>'Wiltshire' }, 'Ring of Brodgar' => { name =>'Ring of Brodgar', mapref =>'HY 294 133', location =>'Orkney' } );
### Untie and retie to show data is stored in the file untie %database1; tiemy %database2, 'MLDBM', 'mldbmtest.dat', O_RDWR, 0666 ordie"Can't initialize MLDBM file: $!\n";
### Dump out via Data::Dumper what's been stored ... print Data::Dumper->Dump( [ \%database2 ] );
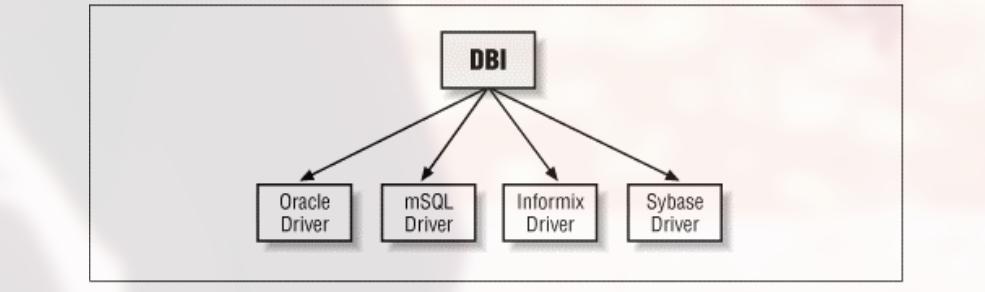
my @list = DBI->available_drivers(); showarray(\@list);
返回值如:
1 2 3 4 5 6 7 8 9 10
CSV DBM ExampleP File Gofer Mem Proxy SQLite Sponge mysql
DBI->data_sources() 用 DBI->available_drivers() 的一个或多个返回值作为参数, 其罗列出 which data sources are known to the driver. (一般放在 eval {} 中, 因为其会实际加载对应的 driver, 如果不能加载和初始化, 则会 die)
使用如:
1 2
my @list = DBI->data_sources("CSV"); showarray(\@list);
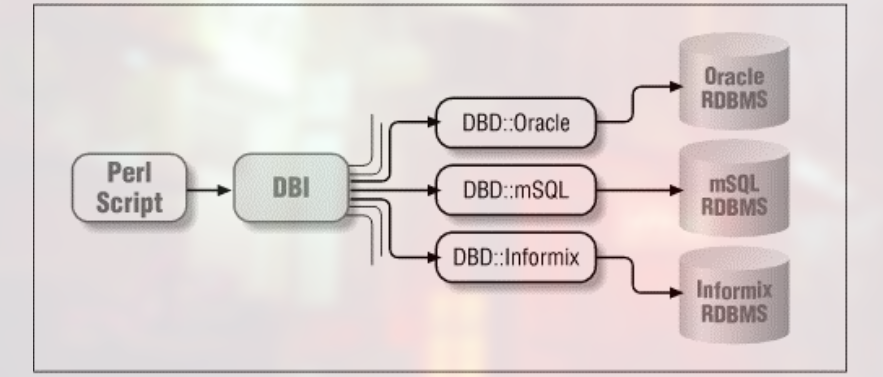
use DBI; # Load the DBI module ### Perform the connection using the Oracle driver
my $dbh = DBI->connect( "dbi:Oracle:archaeo", "username", "password" ) ordie"Can't connect to Oracle database: $DBI::errstr\n"; exit;
error message 存放在变量 $DBI::errstr 中.
同时连接同一个数据库两次如:
1 2 3 4 5 6 7 8
use DBI; # Load the DBI module ### Perform the connection using the Oracle driver my $dbh1 = DBI->connect( "dbi:Oracle:archaeo", "username", "password" ) ordie"Can't make 1st database connect: $DBI::errstr\n"; my $dbh2 = DBI->connect( "dbi:Oracle:archaeo", "username", "password" ) ordie"Can't make 2nd database connect: $DBI::errstr\n"; exit;
同时连接两个不同的数据库如:
1 2 3 4 5 6 7 8
use DBI; # Load the DBI module ### Perform the connection using the Oracle driver my $dbh1 = DBI->connect( "dbi:Oracle:archaeo", "username", "password" ) ordie"Can't connect to 1st Oracle database: $DBI::errstr\n"; my $dbh2 = DBI->connect( "dbi:Oracle:seconddb", "username", "password" ) ordie"Can't connect to 2nd Oracle database: $DBI::errstr\n"; exit;
use DBI; # Load the DBI module ### Perform the connection using the Oracle driver my $dbh1 = DBI->connect( "dbi:Oracle:archaeo", "username", "password" ) ordie"Can't connect to Oracle database: $DBI::errstr\n"; my $dbh2 = DBI->connect( "dbi:mSQL:seconddb", "username", "password" , { PrintError =>0 } ) ordie"Can't connect to mSQL database: $DBI::errstr\n";
exit;
4.4.2 Disconnection
让一个 database handle 和其数据库 disconnect:
1
$rc = $dbh->disconnect();
成功断开返回值则为 true, 不然为 false.
具体如:
1 2 3 4 5 6 7 8 9 10 11 12
use DBI; # Load the DBI module ### Perform the connection using the Oracle driver my $dbh = DBI->connect( "dbi:Oracle:archaeo", "username", "password" , { PrintError =>0 } ) ordie"Can't connect to Oracle database: $DBI::errstr\n"; ### Now, disconnect from the database $dbh->disconnect orwarn"Disconnection failed: $DBI::errstr\n";
#!/usr/bin/perl -w # # ch04/error/ex1: Small example using manual error checking. use DBI; # Load the DBI module ### Perform the connection using the Oracle driver my $dbh = DBI->connect( undef, "stones", "stones", { PrintError =>0, RaiseError =>0 } ) ordie"Can't connect to the database: $DBI::errstr\n";
### Prepare a SQL statement for execution my $sth = $dbh->prepare( "SELECT * FROM megaliths" ) ordie"Can't prepare SQL statement: $DBI::errstr\n";
### Execute the statement in the database $sth->execute ordie"Can't execute SQL statement: $DBI::errstr\n";
### Retrieve the returned rows of data my @row; while ( @row = $sth->fetchrow_array( ) ) { print"Row: @row\n"; } warn"Data fetching terminated early by error: $DBI::errstr\n"if $DBI::err;
### Disconnect from the database $dbh->disconnect orwarn"Error disconnecting: $DBI::errstr\n";
#!/usr/bin/perl -w # # ch04/error/mixed1: Example showing mixed error checking modes. use DBI; # Load the DBI module ### Attributes to pass to DBI->connect() to disable automatic ### error checking my %attr = ( PrintError =>0, RaiseError =>0, ); ### The program runs forever and ever and ever and ever ... while ( 1 ) { my $dbh;
### Attempt to connect to the database. If the connection ### fails, sleep and retry until it succeeds ... until ( $dbh = DBI->connect( "dbi:Oracle:archaeo", "username", "password" , \%attr ) ) { warn"Can't connect: $DBI::errstr. Pausing before retrying.\n"; sleep( 5 * 60 ); }
eval { ### Catch _any_ kind of failures from the code within ### Enable auto-error checking on the database handle $dbh->{RaiseError} = 1;
### Prepare a SQL statement for execution my $sth = $dbh->prepare( "SELECT stock, value FROM current_values" ); while (1) { ### Execute the statement in the database $sth->execute( ); ### Retrieve the returned rows of data while ( my @row = $sth->fetchrow_array() ) { print"Row: @row\n"; } }
### Pause for the stock market values to move sleep60; }; warn"Monitoring aborted by error: $@\n"if $@; ### Short sleep here to avoid thrashing the database sleep5; }
use DBI; # Load the DBI module ### Attributes to pass to DBI->connect() to disable automatic ### error checking
my %attr = ( PrintError =>0, RaiseError =>0, );
### Perform the connection using the Oracle driver my $dbh = DBI->connect( "dbi:Oracle:archaeo", "username", "password" , \%attr ) ordie"Can't connect to database: ", $DBI::errstr, "\n";
### Prepare a SQL statement for execution my $sth = $dbh->prepare( "SELECT * FROM megaliths" ) ordie"Can't prepare SQL statement: ", $dbh->errstr(), "\n";
### Execute the statement in the database $sth->execute ordie"Can't execute SQL statement: ", $sth->errstr(), "\n";
### Retrieve the returned rows of data while ( my @row = $sth->fetchrow_array() ) { print"Row: @row\n"; } warn"Problem in fetchrow_array(): ", $sth->errstr(), "\n" if $sth->err();
### Disconnect from the database $dbh->disconnect orwarn"Failed to disconnect: ", $dbh->errstr(), "\n";
use DBI; ### The string to quote my $string = "Don't view in monochrome (it looks 'fuzzy')!";
### Connect to the database my $dbh = DBI->connect( "dbi:Oracle:archaeo", "username", "password" , { RaiseError =>1 } );
### Escape the string quotes ... my $quotedString = $dbh->quote( $string );
### Use quoted string as a string literal in a SQL statement my $sth = $dbh->prepare( " SELECT * FROM media WHERE description = $quotedString " ); $sth->execute();
use DBI; ### Declare a list of values my @values = ( 333, 'Choronzon', 'Tim', undef, 'Alligator', 1234.34, 'Linda', 0x0F, '0x0F', 'Larry Wall' );
### Check to see which are numbers! my @areNumbers = DBI::looks_like_number( @values );
for (my $i = 0; $i < @values; ++$i ) { my $value = (defined $values[$i]) ? $values[$i] : "undef";
print"values[$i] -> $value ";
if ( defined $areNumbers[$i] ) { if ( $areNumbers[$i] ) { print"is a number!\n"; } else { print"is utterly unlike a number and should be quoted!\n"; } } else { print"is undefined!\n"; } }
### The database handle my $dbh = DBI->connect( "dbi:Oracle:archaeo", "username", "password" );
### The statement handle my $sth = $dbh->prepare( "SELECT id, name FROM megaliths" );
exit;
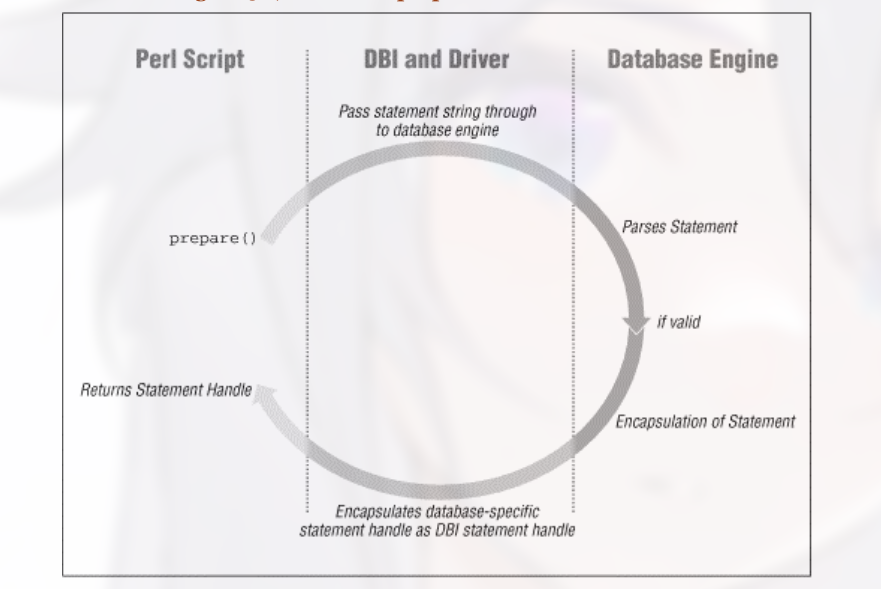
语句有问题则返回 undef.
对于有些 driver 来说, prepare 的步骤实际上到 execute() 时才真正进行.
5.1.1.1 构建 “on-the-fly” 的语句
如:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
### This variable is populated from the online form, somehow... my $siteNameToQuery = $CGI->param( "SITE_NAME" );
### Take care to correctly quote it for use in an SQL statement my $siteNameToQuery_quoted = $dbh->quote( $siteNameToQuery );
### Now interpolate the variable into the double-quoted SQL statement $sth = $dbh->prepare( " SELECT meg.name, st.site_type, meg.location, meg.mapref FROM megaliths meg, site_types st WHERE name = $siteNameToQuery_quoted AND meg.site_type_id = st.id " ); $sth->execute( ); @row = $sth->fetchrow_array( ); ...
这里, 将从 CGI 获取的数据用 quote() 处理后内插到查询语句中.
另一种 动态生成语句 的方法:
1 2 3 4 5 6 7 8 9
### Now build the SQL statement $statement = sprintf"SELECT %s FROM megaliths WHERE name = %s", join(", ", @fields), $dbh->quote($siteNameToQuery);
从 SQL 查询得到的数据一般称为 result set (结果集, 由于关系数据库的机制). Perl 程序利用 result set 的内容需要遍历 each record 或 row. 而这种 row-by-row 获取 result set 数据的形式被称为一个 cursor .
Cursors 用于顺序获取操作, 即 records 是按照其在 result set 中的顺序获取的. 不能跳过一个 record 或者随机访问一个 record.
在一个 record 被 cursor 取出后, 无法被再次取出 (被 forgotten).
因此, 通用的取出数据的方法为: 用循环处理每一行, 直到没有行可取, 如:
1 2 3 4 5 6
while ( records to fetch from $sth ) { ### Fetch the current row from the cursor @columns = get the column values; ### Print it out... print"Fetched Row: @columns\n"; }
### Prepare the SQL statement ( assuming $dbh exists ) $sth = $dbh->prepare( " SELECT meg.name, st.site_type FROM megaliths meg, site_types st WHERE meg.site_type_id = st.id " );
### Execute the SQL statement and generate a result set $sth->execute();
### Fetch each row of result data from the database as a list while ( ( $name, $type ) = $sth->fetchrow_array ) { ### Print out a wee message.... print"Megalithic site $name is a $type\n"; }
当没有数据可以 fetch 时, fetchrow_array 会返回空列表, 此时 while 会视为 false, 然后退出循环.
获取数组引用, 即使用 fetchrow_arrayref() 方法
这个方法相对于 fetchrow_array 有性能上的优势, 其返回一个数组引用.
如:
1 2 3 4 5 6 7
### Fetch the rows of result data from the database ### as an array ref.... while ( $array_ref = $sth->fetchrow_arrayref ) { ### Print out a wee message.... print"Megalithic site $arrayref->[0] is a $array_ref->[1]\n"; } die"Fetch failed due to $DBI::errstr"if $DBI::err;
每一次 fetch 数据时, 都使用同一个 ref, 因此以下处理无法得到想要的数据:
1 2 3 4 5 6 7 8 9 10 11 12
### The stash for rows... my @stash;
### Fetch the row references and stash 'em! while ( $array_ref = $sth->fetchrow_arrayref ) { push @stash, $array_ref; # XXX WRONG! }
### Fetch rows into a hash reference while ( $hash_ref = $sth->fetchrow_hashref ) { print"Megalithic site $hash_ref->{name} is a $hash_ref->{site_type}\n"; }
注意 , 有些数据库会将字段名设置为 all uppercase or lowercase characters, 这种情况下就会访问失败.
### Fetch rows into a hash reference with lowercase field names while ( $hash_ref = $sth->fetchrow_hashref('NAME_lc') { print"Megalithic site $hash_ref->{name} is a $hash_ref->{site_type}\n"; }
另一个需要注意的 是, 当你用 完全限定的字段名称 来查询时, 如:
1
SELECT megaliths.id ...
大多数的数据库都会只返回 id 作为字段名. 而当你有:
1
SELECT megaliths.id, media.id ...
时就会出错.
解决方法是 对列名起别名, 如:
1
SELECT megaliths.id AS meg_id, media.id AS med_id ...
5.1.3.1 fetch 和 print 的快速方法
DBI 的 dump_results() 方法能够获取并打印一个 statement handle 的 result set 中的所有行.
这个方法可以由一个 prepared and executed statement handle 来运行.
### Assuming a valid database handle exists.... ### Delete the rows for Stonehenge! $rows = $dbh->do( " DELETE FROM megaliths WHERE name = 'Stonehenge' " );
其返回值 为影响到的行数, 或者 undef.
有些操作不返回行数, 成功执行则返回 -1.
如果没有影响任意行, 但也成功运行, 则返回 0E0, 表示 0.
5.3 给 Statements 绑定参数
有三种传递参数的方式:
placeholders
parameters
binding
绑定也需要用 placeholder, 以及 bind_param() 方法, 如:
1 2 3 4 5 6
$sth = $dbh->prepare( " SELECT name, location FROM megaliths WHERE name = ? " ); $sth->bind_param( 1, $siteName );
注意, bind_param 方法需要运行在 execute() 之前.
绑定多个值时:
1 2 3 4 5 6 7 8 9 10
$sth = $dbh->prepare( " SELECT name, location FROM megaliths WHERE name = ? AND mapref = ? AND type LIKE ? " ); $sth->bind_param( 1, "Avebury" ); $sth->bind_param( 2, $mapreference ); $sth->bind_param( 3, "%Stone Circle%" );
$sth = $dbh->prepare( " SELECT meg.name, meg.location, st.site_type, meg.mapref FROM megaliths meg, site_types st WHERE name = ? AND id = ? AND mapref = ? AND meg.site_type_id = st.id " );
### No need for a datatype for this value. It's a string. $sth->bind_param( 1, "Avebury" );
### This one is obviously a number, so no type again $sth->bind_param( 2, 21 );
### However, this one is a string but looks like a number $sth->bind_param( 3, 123500, { TYPE => SQL_VARCHAR } );
### Alternative shorthand form of the previous statement $sth->bind_param( 3, 123500, SQL_VARCHAR );
### All placeholders now have values bound, so we can execute $sth->execute( );
print"Stored procedure returned $ceiling, $floor\n";
5.3.4 不使用 bind_param() 的绑定值
将值传给 execute(), 其会自动调用 bind_param() 如:
1 2 3 4 5 6 7
$sth = $dbh->prepare( " SELECT name, location, mapref FROM megaliths WHERE name = ? OR description LIKE ? " ); $sth->execute( "Avebury", "%largest stone circle%" ); ...
### Perl variables to store the field data in my ( $name, $location, $type ); ### Prepare and execute the SQL statement $sth = $dbh->prepare( " SELECT meg.name, meg.location, st.site_type FROM megaliths meg, site_types st WHERE meg.site_type_id = st.id " ); $sth->execute( );
### Associate Perl variables with each output column $sth->bind_col( 1, \$name ); $sth->bind_col( 2, \$location ); $sth->bind_col( 3, \$type );
### Fetch the data from the result set while ( $sth->fetch ) { print"$name is a $type located in $location\n"; }
bind_col() 的第一个参数是列数 (第几列的数据), 第二个参数是获取值的变量引用.
也可以使用 bind_columns() 方法来绑定多行:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
### Perl variables to store the field data in my ( $name, $location, $type );
### Prepare and execute the SQL statement $sth = $dbh->prepare( " SELECT meg.name, meg.location, st.site_type FROM megaliths meg, site_types st WHERE meg.site_type_id = st.id " ); $sth->execute( );
### Associate Perl variables with each output column $sth->bind_columns( undef, \$name, \$location, \$type );
### Fetch the data from the result set while ( $sth->fetch ) { print"$name is a $type located in $location\n"; }
5.5 do() 方法和 prepare() 方法的对比
需要重复使用的 SQL 语句用 prepare() 比较高效, 如:
1 2 3 4 5 6 7 8
### Setup the statement for repeated execution $sth = $dbh->prepare( "INSERT INTO megaliths ( name ) VALUES ( ? )" );
### Iterate through the various bits of data... foreach $name ( qw( Stonehenge Avebury Castlerigg Sunhoney ) ) { ### ... and insert them into the table $sth->execute( $name ); }
### Assuming a valid $dbh exists... ( $name, $mapref ) = $dbh->selectrow_array( "SELECT name, mapref FROM megaliths" ); print"Megalith $name is located at $mapref\n";
#!/usr/bin/perl -w # # ch05/fetchall_arrayref/ex1: Complete example that connects to a database, # executes a SQL statement, then fetches all the # data rows out into a data structure. This # structure is then traversed and printed. use DBI; ### The database handle my $dbh = DBI->connect( "dbi:Oracle:archaeo", "username", "password" , { RaiseError =>1 });
### The statement handle my $sth = $dbh->prepare( " SELECT name, location, mapref FROM megaliths " );
### Execute the statement $sth->execute( );
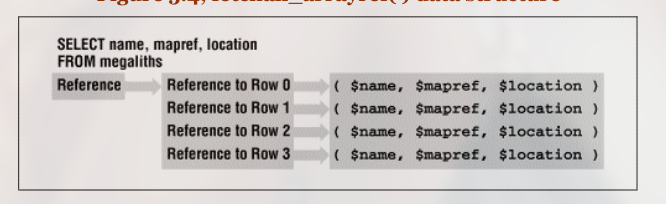
### Fetch all the data into a Perl data structure my $array_ref = $sth->fetchall_arrayref( );
### Traverse the data structure and dump each piece of data out ### ### For each row in the returned array reference ... foreachmy $row (@$array_ref) { ### Split the row up and print each field ... my ( $name, $type, $location ) = @$row; print"\tMegalithic site $name, found in $location, is a $type\n"; } exit;
#!/usr/bin/perl -w # # ch05/fetchall_arrayref/ex3: Complete example that connects to a database, # executes a SQL statement, then fetches all the # data rows out into a data structure. This # structure is then traversed and printed. use DBI;
### The database handle my $dbh = DBI->connect( "dbi:Oracle:archaeo", "username", "password" , { RaiseError =>1, } );
### The statement handle my $sth = $dbh->prepare( " SELECT name, location, mapref FROM megaliths " );
### Execute the statement $sth->execute( );
### Fetch all the data into an array reference of hash references! my $array_ref = $sth->fetchall_arrayref( { name =>1, location =>1 } );
### Traverse the data structure and dump each piece of data out ### ### For each row in the returned array reference..... foreachmy $row (@$array_ref) { ### Get the appropriate fields out the hashref and print... print"\tMegalithic site $row->{name}, found in $row->{location}\n"; } exit;