PWN-B-站-学习
什么是 pwn
Pwn 是一个计算机安全领域中的术语,指的是攻击者(或者比赛选手)通过利用程序中的漏洞,获取对目标计算机系统的控制权。Pwn 是 “own” 的变体,表示攻击者已经完全控制了目标系统。
通常,pwn 攻击是通过利用程序中的缓冲区溢出、格式化字符串漏洞、整数溢出等漏洞实现的。攻击者通过利用这些漏洞,可以获取目标系统的 root 权限、执行任意代码、修改系统状态等等。
Pwn 通常是 CTF (Capture The Flag) 比赛中的一种常见题型,选手需要通过分析程序并利用漏洞,获取指定的 flag。Pwn 也是计算机安全领域中的重要研究方向,涉及到漏洞分析、二进制代码编写、ROP 技术等方面的知识和技能。
1 环境配置
可能用到的工具:
- IDA Pro
- pwntools
- pwndbg
- checksec
- ROPgadget
- one_gadget
- LibcSearcher
- main_arena_offset
IDA Pro 用于静态分析.
什么是静态分析
静态分析是一种在不实际运行程序的情况下分析代码结构、语法和语义的方法。这种分析技术通常用于检查代码中的错误、漏洞、安全问题、性能问题、代码质量等方面。
在静态分析中,程序代码被解析并转换为中间表示形式,然后通过分析这个中间表示形式来识别潜在问题。这种分析可以通过手工检查或使用自动化工具实现。
静态分析可以应用于许多不同类型的程序,包括编译器、解释器、脚本、库和应用程序。这种技术可以帮助开发人员在开发过程中及时发现和修复代码中的问题,提高代码质量和可维护性。同时,它也可以用于安全审计和漏洞扫描等方面,以帮助发现和修复潜在的安全风险。
如何安装 pwntools
安装 pwntools, 用于攻击的模块:
1 | |
若遇到 externally managed environment 的报错, 看另一篇文章.
安装完 pwntools 后会包含 checksec 工具
checksec 的作用
checksec 是一个安全工具,用于检查 ELF 格式的二进制文件的安全保护机制是否启用。它可以帮助用户评估二进制文件的安全性,并确定它们在系统上的可靠性。
checksec 工具可以检查以下安全保护机制是否启用:
- 栈保护(stack canaries):在函数调用时,检查程序的栈是否被恶意代码修改,从而防止栈溢出攻击。
- RELRO(RELocations Read-Only):在程序加载时,将 ELF 文件中的重定位表(Relocation Table)标记为只读,以防止攻击者修改程序的全局偏移量表(GOT)等重要数据结构。
- NX(No eXecute):使得内存中的代码段不能被直接执行,以防止攻击者在程序运行时注入恶意代码。
- PIE(Position Independent Executable):将程序编译为位置无关的可执行文件,使得程序在内存中的位置随机化,以防止攻击者利用可预测的地址进行攻击。
checksec 工具可以为 ELF 文件提供一个安全性的概览,它可以告诉用户哪些安全保护机制被启用,哪些没有被启用,并提供一些建议来提高二进制文件的安全性。
也会包含 ROPgadget 工具:
ROPgadget 的作用
ROPgadget 是一个用于寻找 ROP(Return Oriented Programming)链的工具。ROP 是一种利用程序中已存在的代码片段(称为gadgets)创建攻击代码的技术,可以绕过栈随机化和代码注入检测等防御机制,对软件漏洞进行攻击。
ROPgadget 工具可以对二进制文件进行扫描,从中找到可用的 gadgets,并将它们组合成 ROP 链。它可以帮助攻击者自动化地构建 ROP 链,从而简化攻击的过程。同时,ROPgadget 工具也可以帮助防御者评估系统的安全性,发现系统中可能存在的 ROP 攻击漏洞。
ROPgadget 工具可以执行以下任务:
- 扫描 ELF 文件中的可执行代码,寻找符合要求的 ROP gadgets。
- 输出符合要求的 ROP gadgets 的地址和指令码等信息。
- 组合 ROP gadgets,构建 ROP 链,输出 ROP 链的地址和指令码等信息。
- 支持多种架构和指令集,包括 x86、x64、ARM、MIPS 等。
- 支持多种操作系统,包括 Linux、Windows、macOS 等。
动态分析
用 pwngdb, 也就是 gdb 的 pwn 版.
在 github 找仓库 安装.
Archlinux 可直接用 yay 安装:
1 | |
(可以用 peda 或 gef 替换 pwngdb)
one_gadget 的作用
one_gadget 是一个用于自动查找可用于构造 ROP 链的 gadget 的工具,通常用于利用二进制文件中的漏洞进行攻击。
需安装 ruby 以及其包管理器. 在 Archlinux 上:
1 | |
注意添加 $HOME/.local/share/gem/ruby/3.0.0/bin 到 $PATH 中.
LibcSearcher 的使用
用网站 Libc Database
2 ELF 文件概述
三个术语:
- exploit, 指脚本与方案
- payload, 指用于触发漏洞的数据
- shellcode, 指 shell 代码
C 代码编译过程:
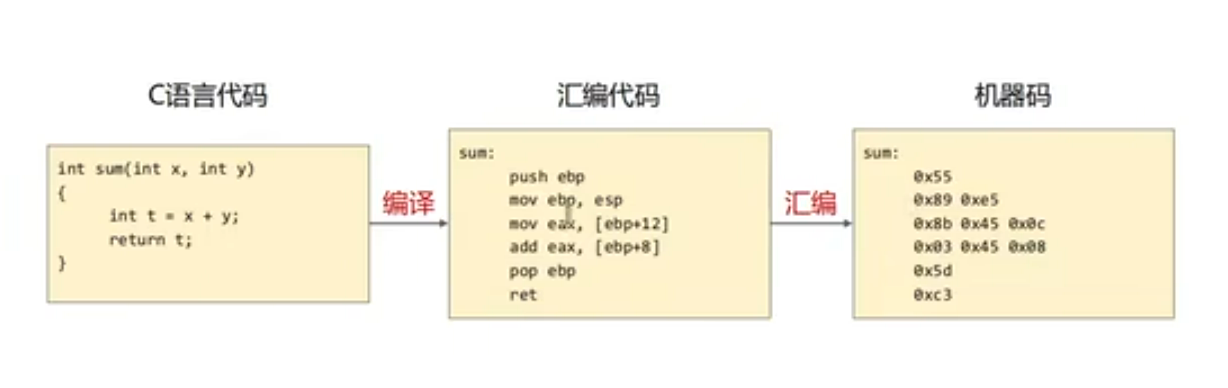
可执行文件分类
- Windows: PE (Portable Executable)
- 可执行程序:
.exe - 动态链接库:
.dll - 静态链接库:
.lib
- 可执行程序:
- Linux: ELF (Excutable and Linkable Format)
- 可执行程序:
.out - 动态链接库:
.so - 静态链接库:
.a
- 可执行程序:
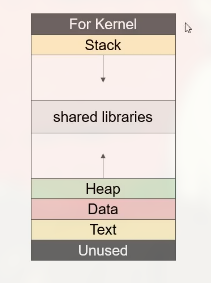
ELF 文件结构
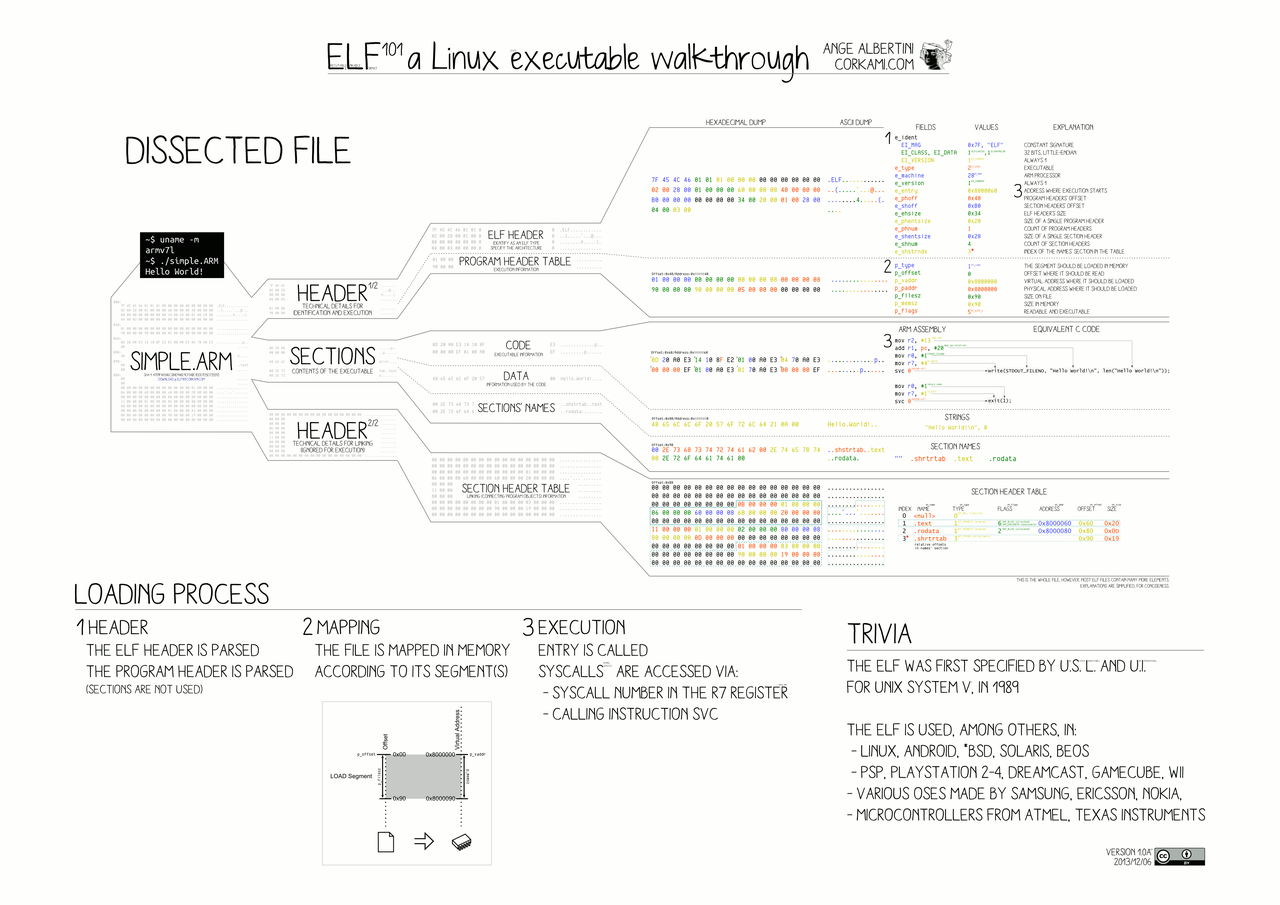

3 程序装载与虚拟内存
节视图用于磁盘中, 段视图用于内容中:
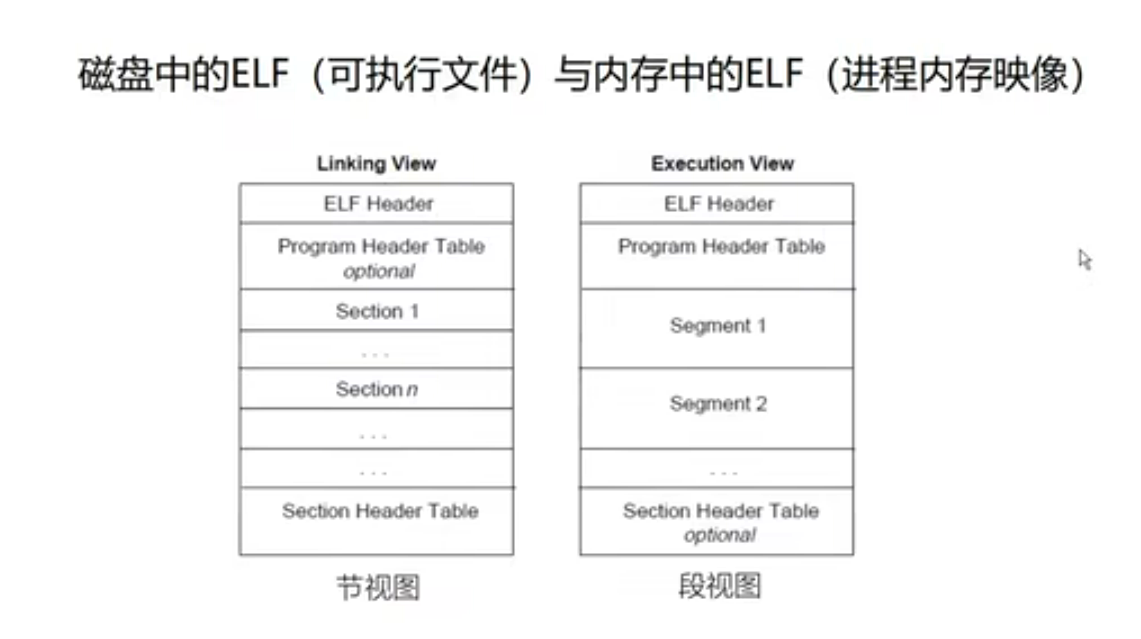
磁盘中的 ELF 映射到内存中的 ELF 的过程:
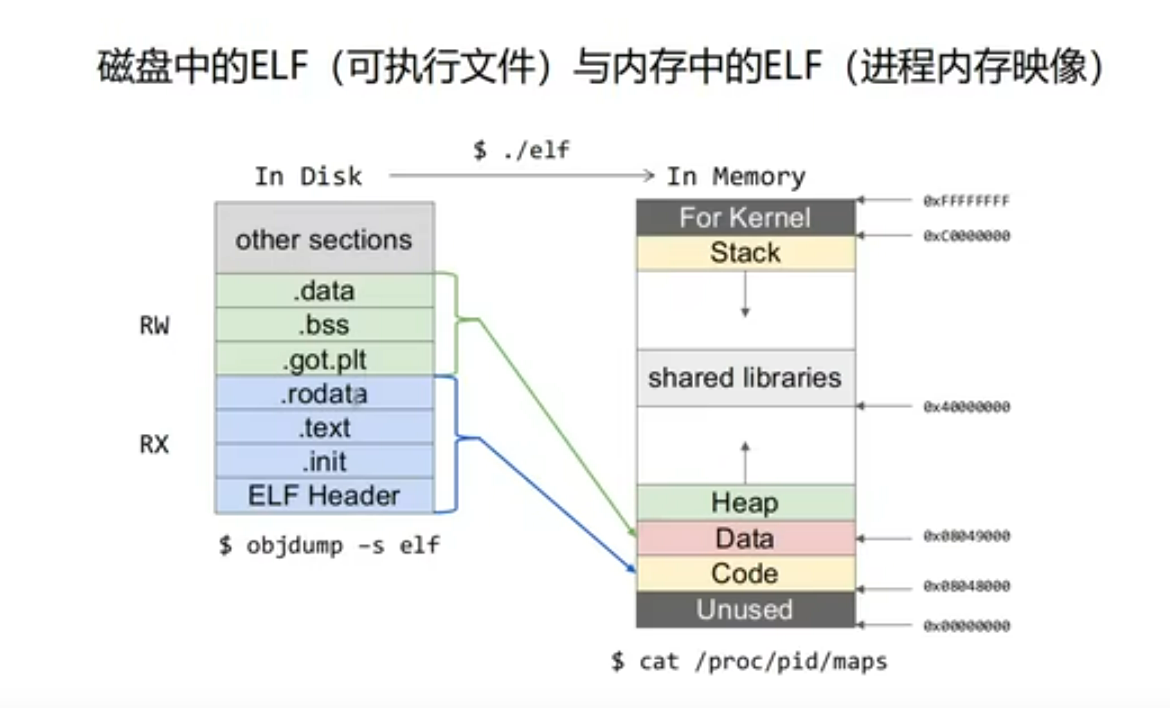
RW (Read 和 Write 权限) 的映射为 Data
RX (仅 Read 权限) 的映射为 Code
注意: 内存映像中 ELF 原始的内容只占一部分.
不同操作系统映射完成的映射空间是不同的.
注意几个点:
- 虚拟内存用户空间每个进程一份, 也就是每创建一个进程, 都会分配一个连续的虚拟内存空间
- 虚拟内存内核空间所有进程共享一份
- 虚拟内存 mmap 段中的动态链接库仅在物理内存中装载一份 (尽管其被 “载入” 多次, 但在内存中只存在一份)
CPU 调用的实际上是物理内存, 但我们看到的是一段连续的内存, 也就是虚拟内存.
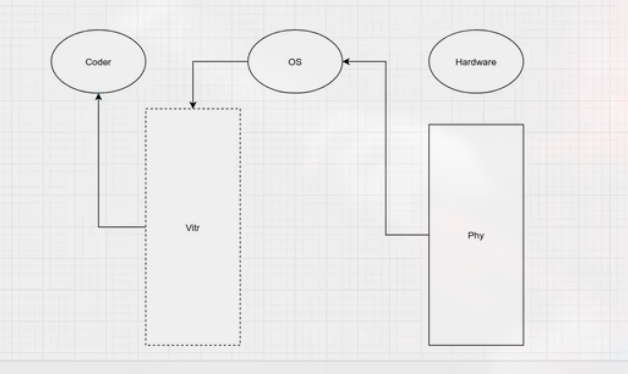
这里涉及分页机制.
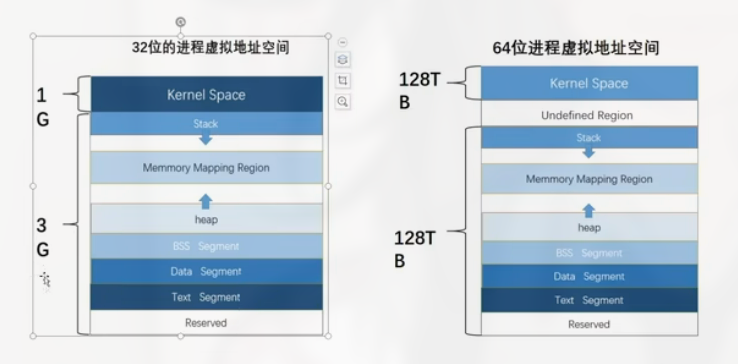
虚拟内存默认大小一般是 4GB (32 位机器, $2^{32}$), 其组成为:
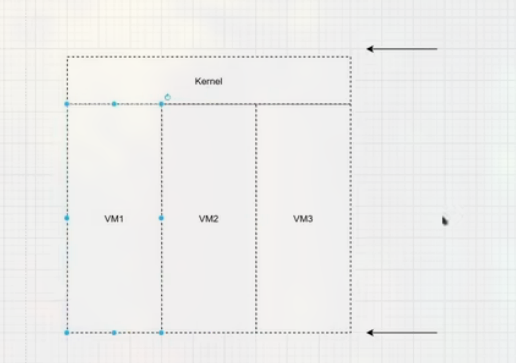
1GB 为内核空间 (公用, 相当于复用).
3GB 为用户空间 (每个进程一份).
内核和挂载的驱动的作用为管理硬件, 其运行在内核空间中
32 位和 64 位的结构:
stack 主要用于程序的控制, 也就是恢复与运行.
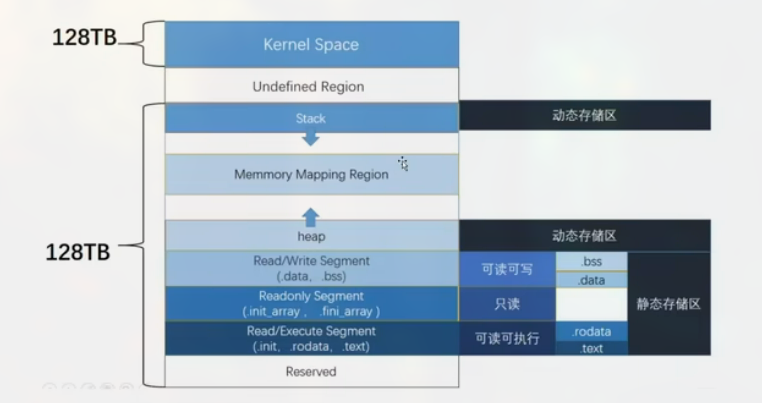
这里可以区分下静态内存区和动态内存区:
4 CPU 与进程执行
段 (segment) 与节 (section)
节视图 存在于 ELF 文件编译链接时.
段视图 存在于进程的内存区域的权限划分.
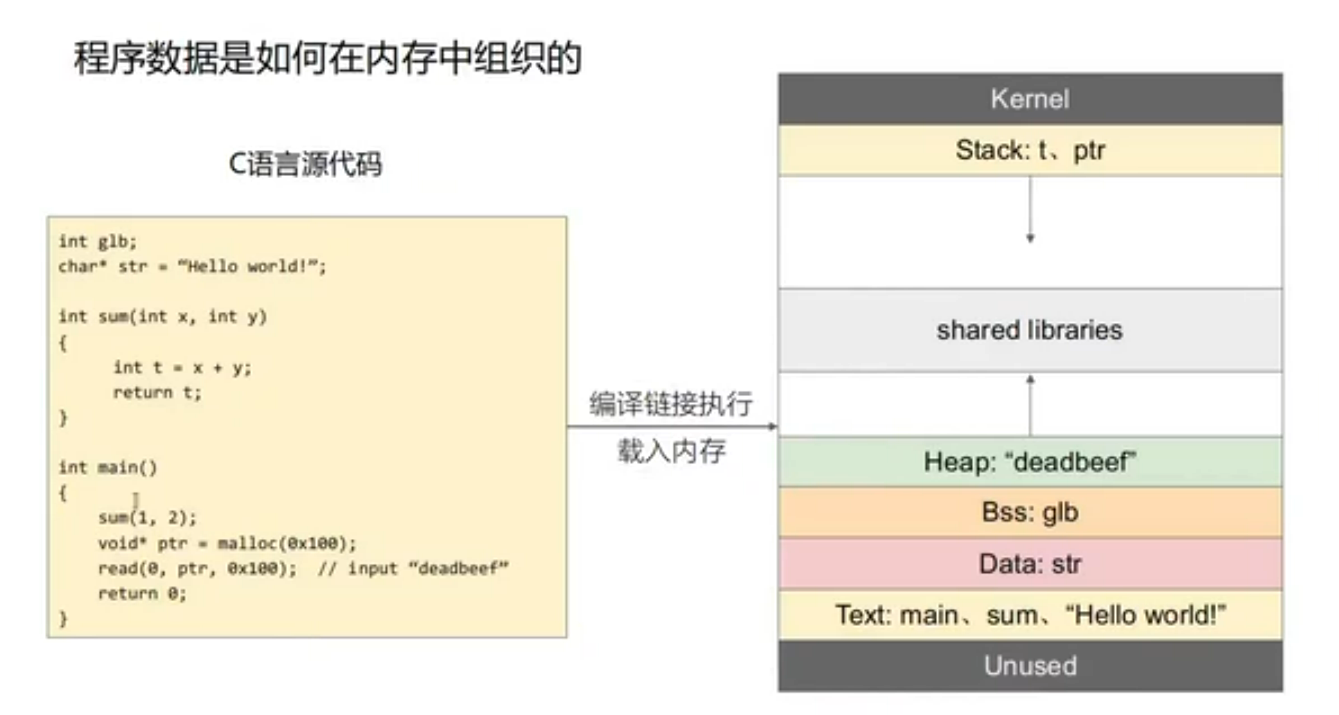
Bss 段放置未初始化的全局变量, 也就是占用内存而不占用磁盘空间的内容.
局部变量存放在 栈 中.
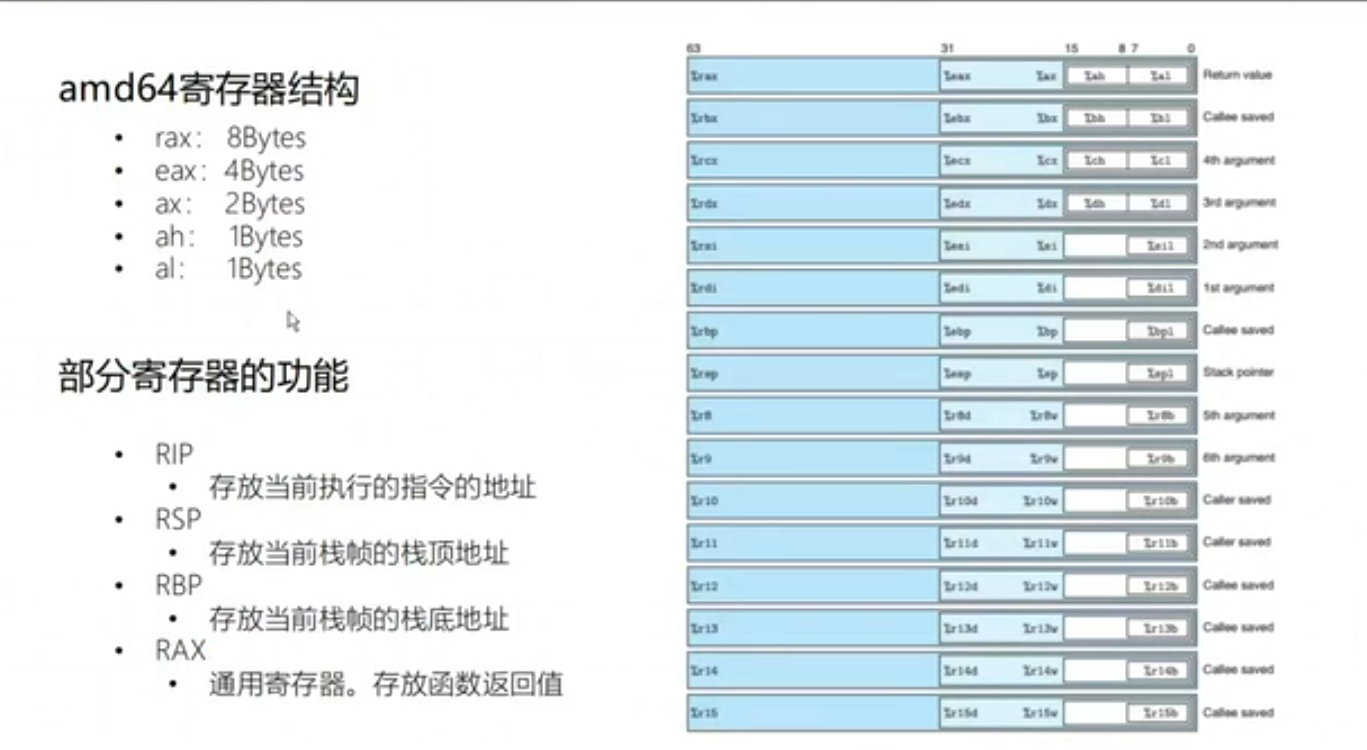
CPU 内嵌的 Register 会存储一些计算的中间结果.
区份 amd64 汇编中常见寄存器:
5 装载与汇编
静态链接生成的可执行程序相较于动态链接生成的可执行程序大得多.
动态链接在可执行文件中填入动态库的地址以方便调用.
静态链接的程序和动态链接的程序的执行过程如下:
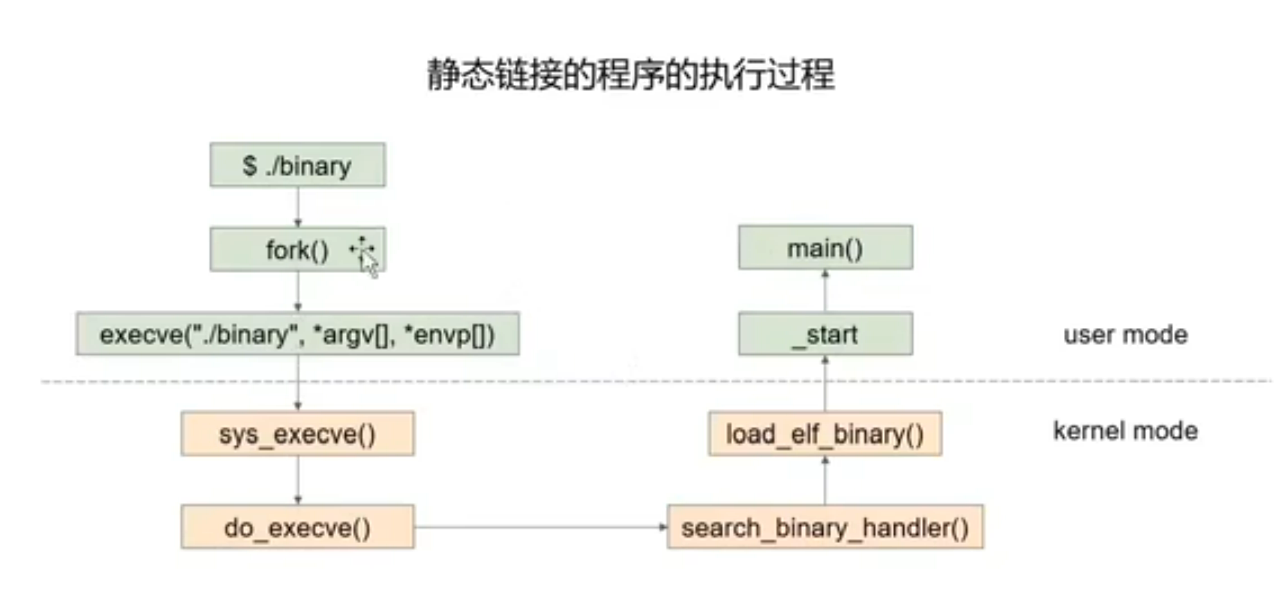
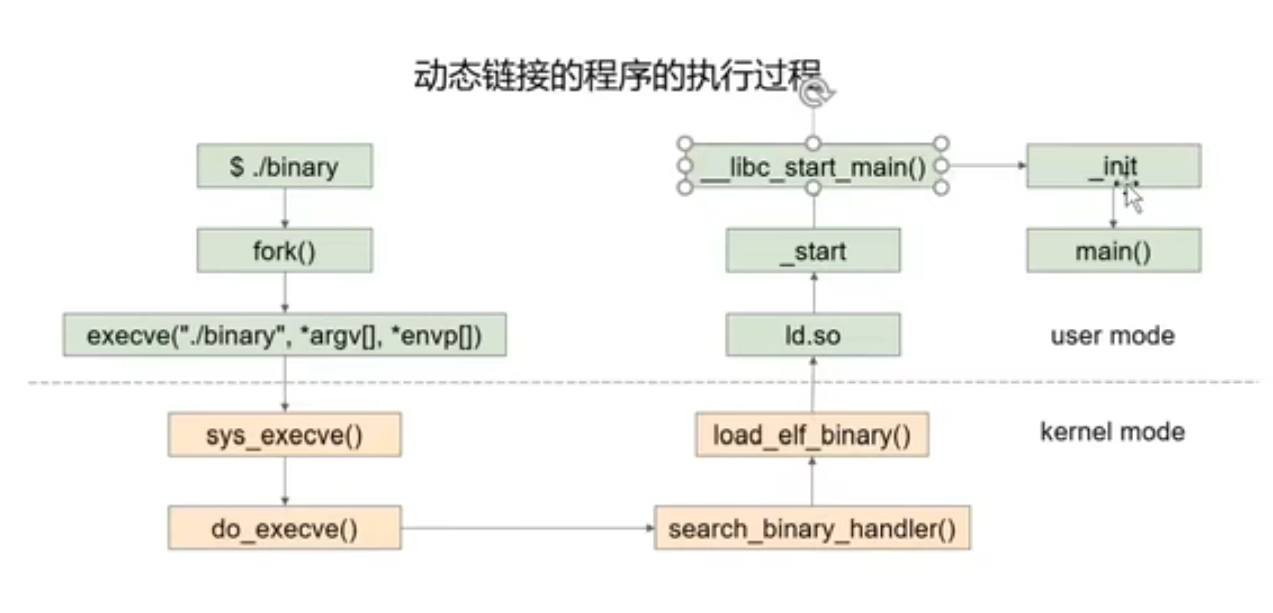
汇编语言就是机器码的助记符.
注意两种汇编格式:

注意溢出只发生在有符号数.
6 Shellcode
shellcode 通常是软件漏洞利用过程中使用的一小段机器代码.
如:
1 | |
需注意, shellcode 允许输入普遍较短, 一般只有几十个字节. 且无法调用系统函数.
解决方法
- 触发中断 (
int 0x80或者syscall), 进行系统调用 - 用
execve()(execute with vector of arguments and environment) 函数
如:
1 | |
在汇编语言中,”global _start” 是一条指示符,用于告诉编译器将 _start 标号(label)导出为全局符号(global symbol),以便其他模块或者链接器可以使用。
在这段汇编代码中,_start 是程序的入口点,也就是程序的起始地址。由于 _start 是一个全局符号,链接器可以根据这个符号将当前模块的代码与其他模块的代码进行链接,从而生成可执行文件。如果没有使用 “global _start” 指令,那么链接器就无法识别 _start 标号,并且在链接时会报错。
需要注意的是,在一些汇编语言中,入口点的名称并不是固定的,可以使用其他名称代替。例如在 NASM(Netwide Assembler)中,可以使用 “global _main” 以及 “section .text ; global _start ; _start:” 等方式来指定程序的入口点。
64 位系统调用和 32 位系统调用的区别
- 穿参寄存器不同
- 系统调用使用 syscall
64 位示例:
1 | |
快速生成 shellcode 的方法
- 使用 pwntools, 设置目标架构, 之后就可以生成 shellcode
如:
1 | |
结果会生成:
1 | |
7 栈溢出基础
几个知识点:
- 函数调用栈是指程序运行时内存一段连续的区域, 用来保存函数运行时的状态信息, 包括函数参数与局部变量等
- 发生函数调用时, 调用函数的状态被保存在栈内, 被调用函数的状态压入调用栈的栈顶
- 在函数调用结束时, 栈顶的函数状态被弹出, 栈顶恢复到调用函数的状态
- 函数调用栈在内存中从高地址向低地址生长, 即在压栈时变小, 在退栈时变大
三个重要的寄存器:
esp(stack pointer), 用于指向当前栈顶的地址,也就是栈的最后一个元素的地址。ebp(base pointer), 用于指向栈帧的基址。栈帧是一个包含局部变量、函数参数、返回地址等信息的数据结构,它通常被存储在栈上。ebp 寄存器通常在函数调用时被用来保存上一个栈帧的基址,并且在函数返回时恢复该基址值。eip(instruction pointer), 用于存储下一条将要执行的指令的地址。当 CPU 执行一条指令时,它会从 eip 寄存器中读取下一条指令的地址,并将该地址加载到指令缓存中。然后 CPU 会执行该指令,并更新 eip 寄存器的值,使其指向下一条要执行的指令。
ebp 在函数运行时不变, 可以用来索引确定函数参数或局部变量的位置.
cpu 依照 eip a的存储内容读取指令并执行, eip 随之指向相邻的下一条指令.
函数调用栈的过程
- 被调用函数的参数按照逆序依次压入栈中, 这些参数和之后压入的数据都作为函数的状态来保存
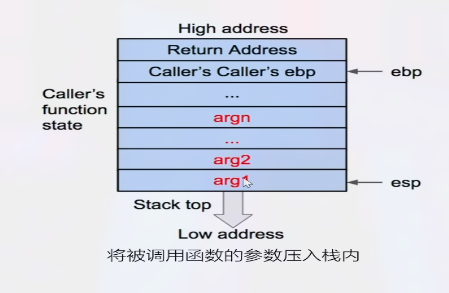
- 将调用函数进行调用之后的下一条指令地址作为返回地址压入栈中, 使得
eip信息得以保存
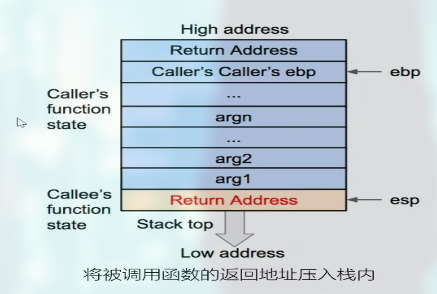
- 将当前
ebp寄存器的值压入栈中, 并将ebp寄存器的值更新为当前栈顶的地址, 这样调用函数的ebp信息得以保存, 同时ebp被更新为调用函数的基地址
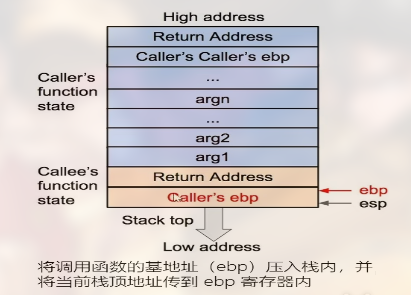
- 将被调函数的局部变量等数据压入栈内
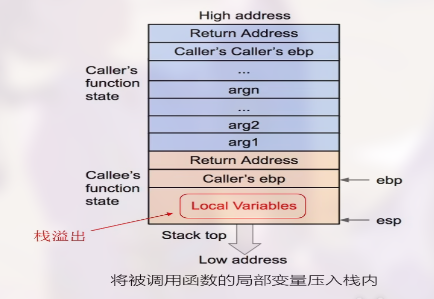
弹出的过程:
- 弹出局部变量
- 弹出
ebp的值给ebp - 弹出
return address给eip - 按序弹出其他
缓冲区溢出 (Buffer overflow)
定义: 编写程序时, 没有考虑到控制或者错误控制用户输入的长度, 本质就是向定长的缓冲区中写入了超长的数据, 造成超出的数据覆写了合法内存区域.
其包括:
- 栈溢出 (Stack overflow)
- 堆溢出 (Heap overflow)
- Data 段溢出
主要思路就是利用栈溢出, 将原本的返回地址改写为指定地址.
解题步骤
- 查看保护措施, 用
checksec命令
注意 gets 函数, 其不对用户输入做限制, 容易造成栈溢出.
同样可以找 backdoor (后门) 函数, 来找目标.
8 canary_pie 绕过
Canary 保护
canary 是一种用来防护栈溢出的保护机制.
其原理是在一个函数的入口处, 先从 fs/gs 寄存器中取出一个 4 字节 (eax) 或者 8 字节 (rax) 的值存到栈上, 当函数结束时会检查这个栈上的值是否和存进去的值一致. 不一致则触发 __Stack_chk_fail 函数导致直接退出.
关于 fs/gs
在x86架构的计算机中,fs和gs是两个特殊的段寄存器,用于存储段选择器。在32位模式下,fs和gs分别存储线程局部存储(TLS)和CPU本地存储(CPU local storage),在64位模式下,fs和gs都可以用于TLS和CPU本地存储
绕过 canary 的思路
- 格式化字符串绕过 canary
- 通过格式化字符串读取 canary 的值
- Canary 爆破 (针对有 fork 函数的程序)
- fork 作用相当于自我复制, 每一次复制出来的程序, 内存布局都是一样的, 因此 canary 值也一样, 然后通过逐位爆破来找到哪一位是 canary
- Stack smashing (故意触发
canary_ssp leak) - 劫持
__stack_chk_fail- 修改
got表中__stack_chk_fail函数的地址, 在栈溢出后执行该函数, 但由于该函数的地址被修改, 所以程序会跳转到我们想要执行的地址
- 修改
最常用的为 格式化字符串.
canary 的特点, 最后两个一定是 00, 如:
PIE 保护
PIE 技术是一个针对代码段 (.text), 数据段 (.data), 未初始化全局变量段 (.bss) 等固定地址的一个防护技术.
如果程序开启了 PIE 保护, 在每次加载程序时都变换加载地址, 从而不能通过 ROPgadget 等一些工具来辅助.
绕过思路
程序加载地址一般都是以内存也为单位的, 所以程序的基地址最后三个数字一定是 0. 此时的方法是 partial writing (部分写地址)
9 ret2xx
ROP (Return Oriented Programming), 其主要思想是在栈缓冲区溢出的基础上, 利用程序中已有的小片段 (gadgets, 也就是以 ret 结尾的指令序列) 来改变某些寄存器或者变量的值, 从而控制程序的执行流程
使用条件:
- 程序存在溢出, 且可以控制返回地址
- 存在满足条件的 gadgets 且知道 gadgets 的地址
ret2text 指用控制程序来执行程序本身已有的代码.
10 栈溢出进阶
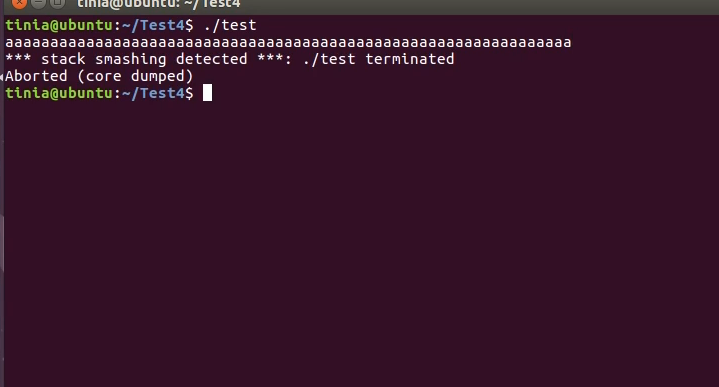
通过报错输出来得到 flag
多进程下的爆破
利用:
1 | |
这里的 pid_t 就是 int
创建一个新进程后, 操作系统会复制父进程的地址空间中的内容给子进程, 调用 fork 函数后, 子进程和父进程的执行顺序是无法确定的.
(此时父进程和子进程的 canary 一致)
子进程无法通过 fork() 来创建子进程.
fork() 的返回值:
- 在父进程中,
fork返回新创建子进程的进程 ID - 在子进程中,
fork返回 0 - 出现错误,
fork返回负数
11 格式化字符串基础
格式化字符串 (format string), 将计算机内存中表示的数据转化为我们人类可读的字符串格式.
C 语言 printf 函数格式化字符串的基本格式:
1 | |

%p (pointer) 用于打印指针变量的值.
%s (string) 用户打印指定地址的数据, 知道遇到 \0.
%n 把已经成功输出的字符写入对应的整形指针参数变量中, 如:
1 | |
%n 是一次写入 4 字节.
%hn 是一次写入 2 字节.
%hhn 是一次写入 1 字节.
__printfA_chk 和 printf 的区别:
- 不能使用
%n$p不连续地打印 - 在使用
%n时会做一些检查
12 堆chunk介绍以及源码剖析
定义: