Slurm-基本使用
介绍
Slurm, Simple Linux Utility for Resource Management, 是一个开源的集群管理和作业调度工具. 比如
- 管理计算资源 (CPU, 内存, 存储) 的分配
- 当用户提交作业时, 根据资源合理调度作业的执行
- 并行计算以及监控作业队列等.
Slurm 也具有扩展性, 可添加插件.
Slurm 有命令行以及可视化工具, 管理比较便利.
基本结构
slurmd
每一个 node 都会运行一个 slurmd 进程.
slurmctld
中心节点运行 slurmctld 进程.
相关命令
所有节点上都能运行: sacct, sacctmgr, salloc, sattach, sbatch, sbcast, scancel, scontrol, scrontab, sdiag, sh5util, sinfo, sprio, squeue, sreport, srun, sshare, sstat, strigger and sview 命令.
(各命令详细一点的介绍和示例在文末)
结构图
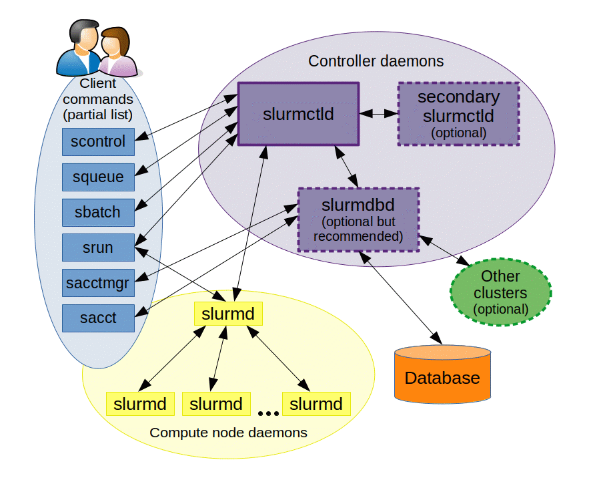
哪个 node 运行命令, 哪个就需要与 slurmctld 交互.
Partitions
可以将节点分组成多个逻辑集合 (也就是分区, 每一个名称唯一), 每个分区就是一个作业队列 (可以添加多个 Jobs, 而每个 Job 包含多个 Job Steps),
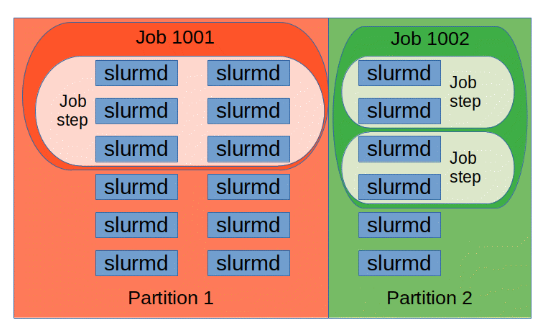
部分概念
MPI
MPI, Message Passing Interface, 是一种用于并行计算的标准协议, 广泛应用于高性能计算 (HPC) 环境. MPI 允许多个计算节点之间进行高效通信, 使得可以在多个处理器上并行执行程序.
命令示例
sacct, “slurm accounting”: 用于报告活动或已完成作业的会计信息, 提供作业或作业步骤的状态salloc, “slurm allocate”: 实时分配作业所需资源, 通常用于分配资源并启动一个 shell, 随后可以使用srun命令来启动并行任务sattach, “slurm attach”: 将标准输入, 输出和错误, 以及信号功能附加到当前运行的作业或作业步骤, 可以多次附加和分离sbatch, “slurm batch”: 提交作业脚本以供后续执行, 脚本通常包含一个或多个srun命令, 用于启动并行任务sbcast, “slurm broadcast”: 从本地磁盘向分配给作业的节点之间传输文件. 适用于无盘计算节点或提高共享文件系统的性能scancel, “slurm cancel”: 用于取消待处理或正在运行的作业或作业步骤. 也可以向所有与运行作业或作业步骤相关的进程发送信号scontrol, “slurm control”: 管理工具, 用于查看和/或修改Slurm状态. 许多scontrol命令需要以 root 用户身份执行sinfo, “slurm information”: 报告Slurm管理的分区和节点状态, 支持多种过滤, 排序和格式化选项sprio, “slurm priority”: 显示影响作业优先级的详细信息squeue, “slurm queue”: 报告作业或作业步骤的状态, 默认按优先级顺序报告正在运行的作业, 然后是待处理的作业, 支持多种过滤和排序选项srun, “slurm run”: 用于提交作业执行或实时启动作业步骤, 支持指定资源需求的多种选项, 包括节点数, 处理器数, 特定节点等sshare, “slurm share”: 显示集群中公平共享的详细信息, 仅在使用优先级/多因素插件时有效sstat, “slurm status”: 获取正在运行的作业或作业步骤所使用的资源信息strigger, “slurm trigger”: 设置, 获取或查看事件触发器, 如节点故障或作业接近时间限制的事件sview, “slurm view”: 提供图形用户界面, 用于获取和更新Slurm管理的作业, 分区和节点的状态信息
sinfo 查看分区和节点信息
1 | |
输出如:
1 | |
- 若分区名有
*, 则说明其为 default partition (如果提交 job 而不指定分区则会交给它) AVAIL列为up, 表示该分区可用- 一个分区的信息分多行显示, 因为其下的 node 状态不同
STATE下的down*, 其中*表示 node 无响应
squeue 查看当前 jobs 信息
1 | |
输出如:
1 | |
ST, “STatus” 列表示 jobs 状态,R表示 “Running”,PD表示 “PenDing”TIME列表明 job 已经运行的时间NODELIST(REASON)列显示 job 在哪个 node 执行, 或者当前 “pending” 的原因, 如Resources或Priority
scontrol 查看 node 详细信息
1 | |
srun 分配资源以及执行 job
1 | |
- 这里没指定 partition, 因此会使用 default partition
-N3表示在三个 nodes 上运行后面的 task-l表示会打印出 job id
也可以指定 partition:
1 | |
创建 4 个 tasks 并分别占用一个 processor, 可以用 -n:
1 | |
sbatch 运行一个脚本
1 | |
-w显示指定要使用的 nodes-o指定将结果输出到哪个文件my.script是要提交的脚本名
脚本 my.script 内容如:
1 | |
以 #SBATCH 开头的行, 可以设置命令行选项 (命令行中设置的优先级更高).
可以用 --gres=<list> 指定 a comma-delimited list of “generic consumable resources”, 格式为 “name[[:type]:count]”, 可以先用 --gres=help 查看有哪些资源可用, 具体示例:
1 | |
输出如:
示例如:
1 | |
运行:
1 | |
指定 Job name
用 --job-name 或 -J 参数, 如:
1 | |
作业数组
当一个程序, 运行多次仅仅是因为传入的参数不同时, 可以用作业数组来运行脚本多次, 通过 index 来更改每次传入的参数.
如:
1 | |
这里创建了一个作业数组, 有 0, 6, 16-32:4 (一个范围, 但是步进为 4, 因此是 5 个数) 这 7 个作业, 作业的 index 可以用 SLURM_ARRAY_TASK_ID 变量来获取.
指定输出文件名
利用: --output=<filename_pattern>, 默认为slurm-%A_%a.out, 具体可用的 pattern 有 (具体可看 man sbatch 的 filename pattern 部分):
%A, 表示 job array 的 id%a, 表示 job array 中某个 job 的 index%j, 表示 job id%u, 表示 user name
salloc 分配资源并返回一个 shell
1 | |