VLLM-内部原理
大模型是如何做 token 生成的
大模型在进行 token 生成时, 通常使用自回归 (autoregressive) 或自编码 (autoencoding) 的方法.
自回归生成
自回归模型在生成每个 token 时, 依赖于之前生成的 token. 这意味着每一步生成的 token 都是基于前面所有生成的 token 以及输入的上下文.
比如 GPT 在生成句子时, 模型会根据已经生成的 token 来预测下一个 token, 比如生成了 今天天气很好, 那么它会根据这个 token 来生成下一个 token, 可能是 想出去玩 之类的.
自编码生成
自编码模型通常是通过对输入进行编码, 然后再进行解码来生成输出. 这种方法常用于填空任务或文本生成.
比如 BERT 处理理解和分类任务时, 在句子 我喜欢[MASK]和咖啡. 中, 模型会被训练来预测被掩盖的 token (在这个例子中可能是 茶).
KV Cache
Key Value Cache, 通过存储复用键值, 让模型不需要重新计算这些键值, 从而加速推理过程.
但是 KV Cache 会占用大量显存, 举一个例子:
KV Cache 占用了大量显存, 但利用率只有 20% ~ 40%, 典型的有三种:
- 预分配的显存, 但不会用到, 比如分配了 1000M, 但只生成了 100M 内容就终止了, 剩下的就浪费了
- 预分配的显存, 但尚未用到, 比如即将生成 1000M 文本, 但在生成 1M 内容时, 1000M 已经分配了, 此时还有 999M 就尚未用到, 浪费了
- 显存之间的间隔碎片, 不足以预分配给下一个文本生成
VLLM 能解决这里的一些浪费问题, 其做的优化有:
- Page Attention
注意力机制
- 不随意 (不随着意识) 线索, 不怎么考虑就处理的线索 (key, 即线索的属性)
- 随意 (随着意识) 线索, 有目的有导向去处理的线索 (query, 即当前关注的问题)
注意力机制, 用于有偏向的选择某些输入 (并不是所有信息都是有用的, 选择有用的进行输入).
解释示例
在侦探工作中,我们经常面临大量的线索,每个线索都由一个属性(key)和其价值(value)组成。这些线索可能包括目击者证词、凶器、不在场证明等,而它们的价值可能各不相同,有的线索价值可能是正的,有的可能是负的,因为某些线索可能会误导调查。
如果我们不采用注意力机制,我们可能需要对所有线索进行平等的调查,这可能导致我们在不重要的线索上花费过多的时间和精力。数学上,这种做法相当于将所有线索的价值简单相加,由于价值有正有负,最终的总价值可能并不高,无法有效指导我们的调查。
然而,通过使用注意力机制,我们可以更加智能地处理这些线索。首先,我们会计算每个线索的属性(key)与我们当前关注的问题(query)之间的相关性。例如,凶器和目击者证词很可能与破案有很高的相关性。然后,我们会将那些与问题高度相关的线索的价值(value)进行加权求和,这样不仅可以保证我们集中精力在最重要的线索上,而且可以提高我们得到有价值信息的可能性。
Paged Attention
Paged Attention 借鉴了操作系统对内存的处理方式.
KV Block 和虚拟显存
操作系统中的虚拟内存和页管理技术, 用来解决给每个应用分配多少内存, 要预分配多少内存, 程序关闭后如何回收内存, 内存碎片如何处理, 怎么最大化地利用内存等问题.
操作系统分配内存是按照最小单位页来分配, 每个页是 4k, 物理内存被划分为很多页, 每个进程要用到的内存被映射到不同的页上: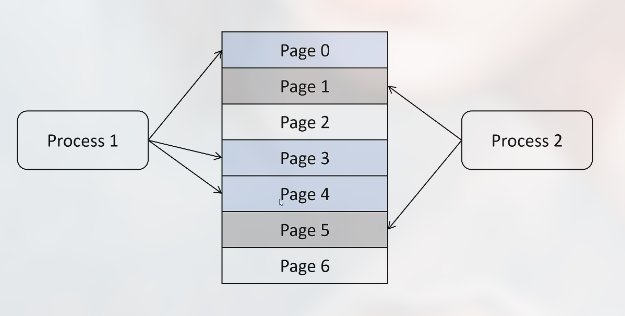
Page Attention 把显存划分为多个 KV Block, 用其管理 KV Cache, 每个请求所需的显存被划分到多个 KV Block 中, 这些 KV Block 可以是不连续的: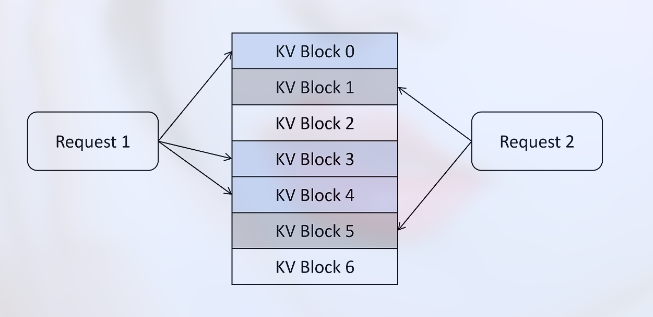
其按需分配, 比如每个 KV Block 能够缓存 4 个 token 的 KV 向量, 当需要存储 16 个 token 的 KV 向量时, 就分配 4 个 KV Block.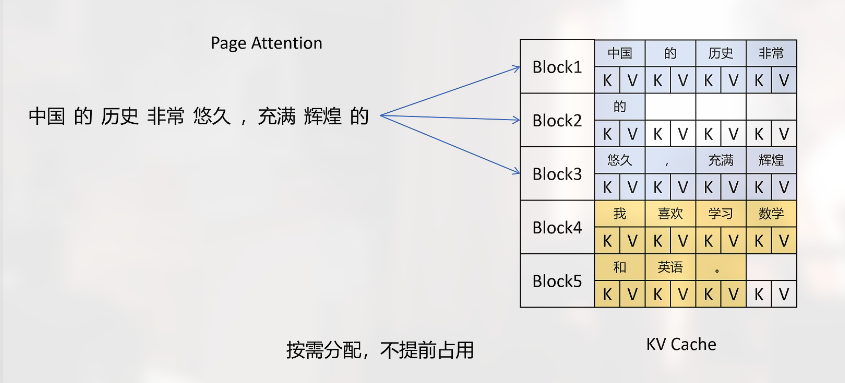
虚拟内存指, 每个请求都有一个逻辑的 KV Cache, 在这里显存似乎是连续的, 这里是通过一个映射表, 再映射到物理的显存中: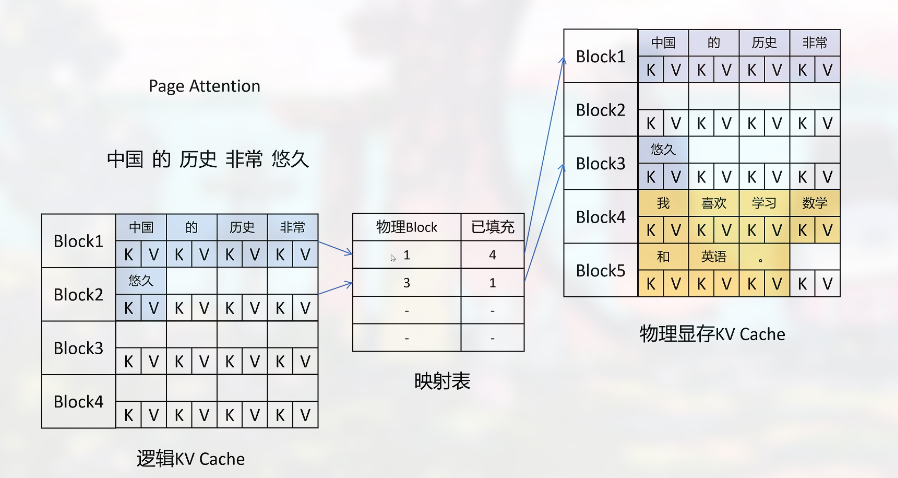
连续的逻辑显存主要是方便程序操作.
Page Attention 利用这种 KV Block 以及虚拟显存来分配, 从而让利用率从 20%~40% 提升到 96%.
Sharing KV Blocks
有时想让大模型用一个 Prompt 生成多个 output, 在 VLLM 里可能是设置 n_beams 参数.
一个 Prompt 生成 KV Cache vector 存储在 KV Cache 中, 当有请求时, 则产生一个引用, 当没有引用时才释放.