Word2Vec-基础
介绍
Word2Vec 不是一个单一的算法, 而是一系列用于从大数据及中学习 word embeddings 的模型结构和优化方式.
两篇相关论文:
- Efficient Estimation of Word Representation in Vector Space
- Distributed Representation of Words and Phrases and their Compositionality
相关概念
Word embeddings
Word embeddings 是一种将单词映射到连续向量空间的表示方式, 使得单词的语义信息在向量中得以保留. 通过这种方式, 不同的单词可以以低维度的向量形式表示, 且相似的单词在向量空间中距离较近.
Continuous bag-of-words model
类似完形填空式预测 word. 根据周围的 context 来预测 middle word.
名字是 “a bag of words”, 就像把所有单词扔进一个袋子里 (你可以把一个单词想象成一个球), 利用袋子里的单词预测缺少的单词, 这种 model 不依赖单词间的顺序.
Continuous skip-gram model
其根据一个中间词预测其一定范围的上下文 (设定一个窗口, 比如 2, 则预测前后各两个单词).
名字是 “skip gram”, 因为其生成单词时跳过了关键词 (也就是一个连续项 gram), 比如用 “sat” 且窗口为 2 得到了 “The cat sat on the” 这五个词, 那么 “sat” 这个就在生成时被跳过了.
Softmax
Softmax 用于将一个实数向量转换为一个概率分布向量 (比如输入 [2.0, 1.0, 0.1], 输出 [0.66, 0.24, 0.10]), 输出值的范围在 0 到 1 之间, 且所有输出值的和为 1.
给定一个实数向量 $z = [z_1, z_2, …, z_n]$, softmax 函数的定义则为:
$$
\displaylines
{
\begin{aligned}
softmax(z_i) = \frac{e^{z_i}}{\sum_{j=1}^n e^{z_j}},\ for\ i=1,2,…,n
\end{aligned}
}
$$
示例, 假设有 $z = [2.0,1.0,0.1]$, 则:
$$
\displaylines
{
\begin{aligned}
e^{z_1} = e^{2.0} \approx 7.39 \newline~ \newline
e^{z_2} = e^{1.0} \approx 2.72 \newline~ \newline
e^{z_3} = e^{0.1} \approx 1.11 \newline~ \newline
Sum = e^{2.0} + e^{1.0} + e^{0.1} \approx 7.39 + 2.72 + 1.11 \approx 11.22 \newline~ \newline
softmax(z_1) = \frac{e^{2.0}}{11.22} \approx 0.66 \newline~ \newline
softmax(z_2) = \frac{e^{1.0}}{11.22} \approx 0.24 \newline~ \newline
softmax(z_1) = \frac{e^{0.1}}{11.22} \approx 0.10 \newline~ \newline
softmax(z) \approx [0.66,0.24,0.10]
\end{aligned}
}
$$
条件概率
条件概率指, 已知某一事件 (B) 发生的条件下, 另一事件 (A) 发生的概率, 记为 $P(A|B)$.
数学定义为:
$$
\displaylines
{
\begin{aligned}
P(A|B) = \frac{P(A \cap B)}{P(B)}
\end{aligned}
}
$$
即 A, B 同时发生的概率除以 B 发生的概率.
注意 A, B 同时发生的概率 $P(A \cap B)$ 不一定等于 $P(A) \times P(B)$, 除非两个事件是独立事件.
若是非独立事件, 那么其需要根据条件概率来计算:
$$
\displaylines
{
\begin{aligned}
P(A \cap B) = P(A|B) \times P(B)
\end{aligned}
}
$$
Negative Sampling
先要理解两个概念:
- positive sample, 表示真实且有相关性的样本
- negative sample, 表示没有相关性或不真实的样本
通过在训练时, 除了使用真实的正样本外, 随机选择一些负样本, 来最大化正样本间的相似度 (不是很懂原理).
Noise Distribution
Noise Distribution 用于生成与目标分布不同的样本 (也就是负样本).
马尔可夫链
官方 tutorial
以训练 continuous skip-gram model 为示例
用 n-grams 的方法来训练, 比如用 “The wide road shimmered in the hot sun” 来训练: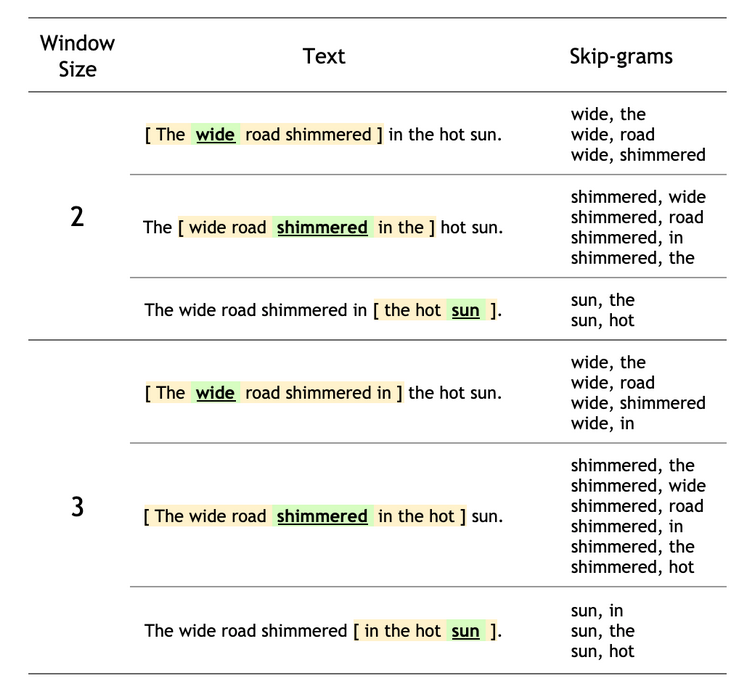
设定好窗口后, 窗口向右移动, 绿色的为 target word, 周围的是 context words.
(剩下的以后读, 现在不是很懂)